可能同步有错误,以前出现过中文编码不能正确同步, 需要把完整的驱动都放到文件夹
D
dazdata 发布的帖子
-
Metabase 替换 logo 教程发布在 Metabase二次开发教程
前置条件
具体步骤
-
纵览,整体修改会修改以下文件

-
修改 logo 组件,组件位置 frontend/src/metabase/components/LogoIcon.jsx,主要替换render 的 svg 即可,拿自己 logo 的 svg 替换掉现有的
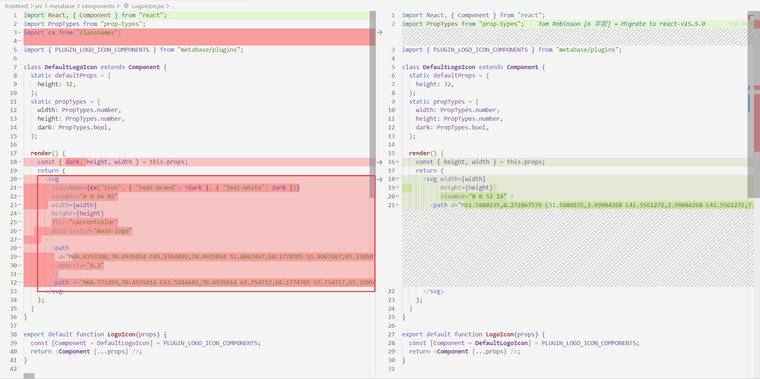
-
修改logo badge 组件,组件位置frontend/src/metabase/public/components/EmbedFrame/LogoBadge.tsx,它主要用在分享页面的底部,这里我们只需要修改下跳转地址即可。像 Metabase 名称这些我们可以通过多语言配置

-
修改语言包,所有语言包都在 locales 目录。这里我们主要修改 Metabase 关键字的翻译
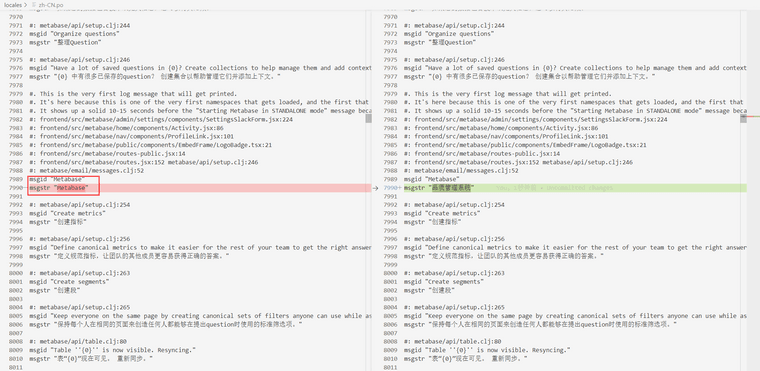
-
替换favicon.ico ,这些都是静态文件在 resource/frontend_client 目录。
-
执行 ./bin/build 打包命令,重新打 jar 包。如果不确定改的是否有问题,可以单独先跑一下前端验证一下。因为打包耗时会相对比较长。
-
-
部署 metabase 为 windows 服务发布在 Metabase技术问题分享
Metabase的部署非常的简单,通常情况下,我们只需安装好jdk(jdk>=11)环境,然后下载好metabase的jar包,直接在终端中运行就可以了。
但是很多的时候我们并不希望使用metabase的时候还要去手动启动一下metabase,这种情况下我们可以通过工具将metabase做成windows里的一个服务(service),这样我们就可以直接通过window的服务对metabase进行管理了。
在这里我们使用到windows服务管理工具为nssm。准备工作:
预期配置:
- metabase 工作目录 :D:\metabase
- nssm.exe 存放目录:D:\metabase
部署步骤:
- 下载好jdk,双击安装。
- 下载好metabase,并放到工作目录(D:\metabase)。
- 下载好nssm.exe,并放到工作目录(D:\metabase)。
- 用管理员权限打开一个CMD终端
#获取java的路径,此时得到的路径是一个类linux的路径,需要你手动转换成windows的路径,或者直接到安装目录找,找到后在地址栏复制路径。 where java #切换盘符到工作目录盘符 D:\ #切换到工作目录 cd D:\metabase #创建服务 ,这个创建的服务名为 metabase ,它后面的第一个路径是 java的路径(即前面获取的Java路径),后面第二个路径是metabase.jar的路径 .\nssm.exe install metabase "C:\Program Files\Eclipse Adoptium\jdk-11.0.16.101-hotspot\bin\java" -jar "D:\metabase\metabase.jar" #配置环境变量,这里只配置MB_JETTY_PORT,如果需要配置更多的环境变量,直接接着这个环境变量继续写 .\nssm.exe set metabase AppEnvironmentExtra MB_JETTY_PORT=8001 #设置服务的工作目录 .\nssm.exe set metabase AppDirectory D:\metabase #设置日志的输入文件 .\nssm.exe set metabase AppStdout D:\metabase\run.log #设置错误日志的输出文件 .\nssm.exe set metabase AppStderr D:\metabase\err.log #启动服务 .\nssm.exe start metabase #如果要查看配置可以执行.\nssm.exe get metabase <配置参数名称>,下面是查所有的环境变量 .\nssm.exe get metabase AppEnvironmentExtra #更多的命令功能可以执行.\nssm.exe -h 查看 -
新一代数据栈将逐步替代国内单一“数据中台”发布在 资讯分享
原文:https://gitee.com/report/china-open-source-2022/advanced-technology#big-data
新一代数据栈将逐步替代国内单一“数据中台”
2021 年,美国硅谷最火爆的词汇就是现代数据栈(Modern Data Stack,简称 MDS),它们是以云原生、开源为背景的一系列全新数据技术引擎。相对于传统的闭源、私有化的数据技术来讲,现代数据栈凭借其开放性及公有云的 SaaS 服务快速得到了大量企业用户的认可。现代数据栈分为若干层次,每个层次相互支持,相互协助,形成一个有机的整体。企业使用的时候,很容易就能利用 SaaS 模式将其整合到一起解决企业数据问题。而开源模式,又给 MDS 生态加入了新的活力,快速发展社区的同时让上下游快速出现新的合作。

近几年,国内出现了大量的开源数据技术。2022 年,这些技术形成了具有上下游的有机集合体,从新一代数据源体系到数据处理体系,再到数据分析、AI 算法体系,逐步相互融合、相互支持形成有机整体。可以看到,国内新一代的数据栈在支持云原生技术基础上,还支持私有云/公有云部署,用新一代的计算引擎、算法、调度、同步机制来支持新一代的数据基础建设。

这些新一代技术栈的流行和商业工具生态的整合,将逐步替代国内单一“数据中台”服务四五个领域的局面。这变得跟美国类似——若干家各自领域的专业企业相互集成,最终给用户提供高效且灵活的专业解决方案。
同时,我也高兴看到,这些开源现代数据栈中很多的商业公司,正在美国、欧洲快速建立社区、SaaS 和相关的商业服务,也有一些公司已经和全球的开源现代技术栈公司进行竞争。整体上,来自国内的新一代的开源现代数据栈(Open-source MDS)现在刚刚兴起。我相信,国内具有大量优秀的开发者、丰富的场景和大量的数据基础,一定会有若干家卓越的开源商业公司出现,最终在全球开源现代数据栈中有一席之地!
-
Metabase学习教程:系统管理-13 LDAP集成发布在 Metabase学习教程
使用LDAP进行身份验证和访问控制
了解如何使用LDAP对用户进行身份验证并管理他们对数据的访问。
身份验证和访问控制对于确保正确的人能够访问他们需要的数据至关重要,并且只有合适的人有这个权限。本教程将向您展示如何将Metabase连接到LDAP以及如何使用来自该LDAP服务器的组信息来控制谁可以查看Metabase中的表。我们不会试图教您LDAP本身,但我们只假设您知道一些基本概念。
设置LDAP
Metabase附带的示例数据库有四个表。这个People包含个人识别信息(PII),所以我们只希望Human Resources部门的人员能够看到它。由于我们的公司已经在使用LDAP进行单点登录(SSO),所以我们想从LDAP中获取有关哪些人是(或不是)HR的信息。我们已经在LDAP中为该公司创建了一个记录:
dn: dc=metabase,dc=com
objectClass: top
objectClass: dcObject
objectClass: organization
o: Metabase
我们还有Farrah(在Human Resources部工作)和Rasmus(不在)的记录:
dn: uid=farrah,dc=metabase,dc=com
objectClass: person
objectClass: inetOrgPerson
cn: Farrah Zubin
mail: farrah@example.metabase.com
givenName: Farrah
sn: Zubin
uid: farrah
userPassword: ------dn: uid=rasmus,dc=metabase,dc=com
objectClass: person
objectClass: inetOrgPerson
cn: Rasmus Verdorff
mail: rasmus@example.metabase.com
givenName: Rasmus
sn: Verdorff
uid: rasmus
userPassword: ------
Farrah和Rasmus的记录并没有说明他们是哪些群体的一部分。相反,我们需要一个单独的Groups 我们用户组的记录,在该记录下,一个groupOfNames指定Farrah和另一个名为Luis的员工所在的记录Human Resources:
dn: ou=Groups,dc=metabase,dc=com
objectClass: top
objectClass: organizationalUnit
ou: Groupsdn: cn=Human Resources,ou=Groups,dc=metabase,dc=com
objectClass: top
objectClass: groupOfNames
description: Human Resources
member: uid=farrah,dc=metabase,dc=com
member: uid=luis,dc=metabase,dc=com
如果您使用OpenLDAP并从头开始设置它,则可能需要修改slapd.conf文件要包含的配置文件cosine.schema和inetorgperson.schema架构文件以及core.schema为了让这个工作。
连接到LDAP
一旦LDAP有了正确的记录,我们就可以使用具有管理员权限的帐户登录到Metabase。我们需要做四件事:- 创建组.
- 告诉Metabase用户可以通过LDAP进行身份验证.
- 指定组可以访问的表.
- 告诉Metabase从LDAP获取组信息.
创建组
首先,我们点击齿轮图标,然后选择管理员设置>People>组然后选择创建组我们称我们的团队为“Human Resources”,但我们不会的在Metabase中添加任何人:我们将依赖LDAP来管理成员资格。
鉴定
下一步是告诉Metabase它可以通过LDAP对用户进行身份验证。为此,我们单击身份验证,启用LDAP,然后填写设置以告知Metabase在哪里可以找到服务器。我们在端口389上使用一个本地实例,我们希望Metabase使用“Manager”帐户访问LDAP。我们所有的人都在Metabase.com,我们可以使用默认的搜索过滤器(按ID或电子邮件地址查找人员)来查找他们。
此时,人们可以通过LDAP登录。为了测试这一点,我们可以打开一个匿名浏览器窗口,以Rasmus或Farrah的身份登录。他们两个都看不到人因为我们还没有告诉Metabase从LDAP获取组信息。
权限
接下来,我们去管理员设置>权限>数据并禁用对People,以便用户在默认情况下看不到该表。然后我们授予访问Human Resources组。(这篇关于沙盒的文章包含有关在Metabase中管理表访问的详细信息。)
集团管理
让我们回到管理员设置。在底部,我们告诉Metabase将组成员身份与LDAP中的信息同步,并且它可以在Metabase.com域。
最后一步是告诉Metabase它的组和LDAP的组是如何相关的。如果我们点击编辑映射和创建映射,我们可以填写在LDAP中标识组的可分辨名称(在本例中,是前面创建的Human Resources组的DN)。然后点击添加,选择LDAP组对应的Metabase组,并保存更改。
这是一个很大的设置。为了测试它,让我们打开一个匿名窗口并以Rasmus的身份登录。果然,拉斯穆斯还是看不见People因为他不是Human Resources部的成员。但是如果我们关闭那个窗口,打开另一个窗口,然后以Farrah的身份登录,我们可以见People。如果我们回到管理员的窗口People,我们可以看到图标,显示谁的帐户来自LDAP,而不是由Metabase管理。
-
Metabase学习教程:系统管理-12 用户审计发布在 Metabase学习教程
审核用户和数据
Metabase的审核工具是监视和遵从性的一个基本特性,但它们也可以帮助您充分利用Metabase实例。
审计是商业版本功能,使管理员能够深入了解人们如何使用他们的Metabase实例。
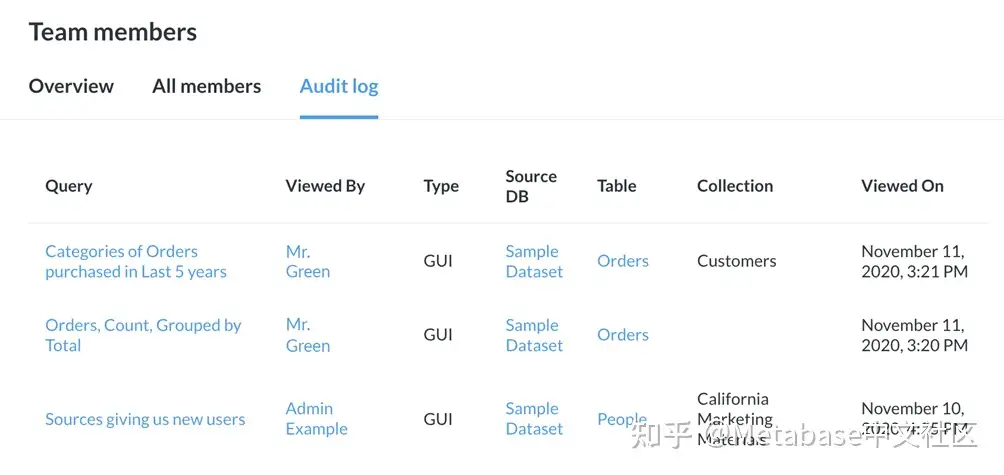
图1。团队成员的审核日志,使管理员可以查看人们如何使用Metabase。
我们将使用包含在Metabase中的示例数据库,通过这些审核工具可以帮助我们的一些示例:
• 看看谁在看什么数据,然后
• 找出机会优化仪表板和查询。
这些审计工具是管理法规遵从性要求的必备工具,但它们也可以帮助我们充分利用我们的数据。
看看谁在看什么数据
在导航侧栏的底部,我们将单击齿轮图标然后选择管理员设置>审计.
谁有权进入“People”表?
这个审核日志可以帮助我们验证数据和收集权限按预期工作。审计日志记录每个表和问题人员视图,它允许我们确认我们遵守了法规遵从性要求。
假设我们想知道谁访问了People表。我们将选择桌子选项卡。如果我们在吧台上徘徊Sample Database PUBLIC PEOPLE,Metabase将显示一个工具提示,其中包含表中特定数量的查询。单击该栏将钻取到该表的审核日志。
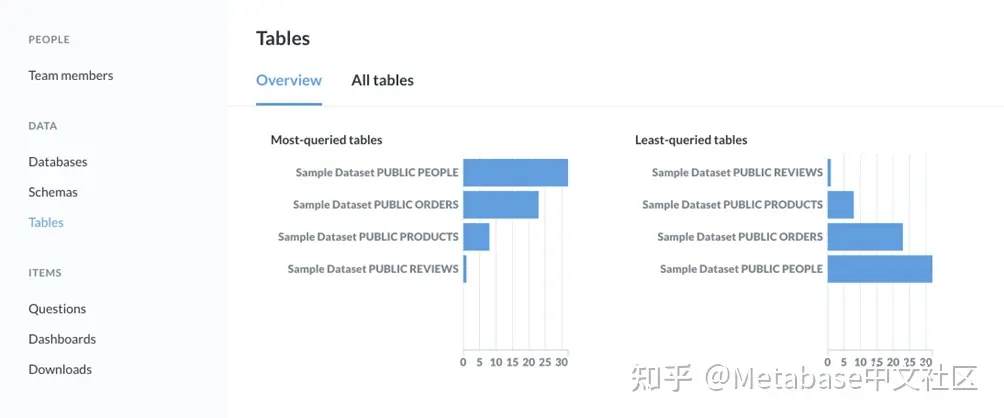
图2。将鼠标悬停在条形图中的PUBLIC PEOPLE项上的“表概述”页。
审计日志表包含三个列:
• 查询人:运行问题的人。
• 查询:执行/查看问题。
• 查看时间:上次查看问题的时间。
表audit log按以下方式对其行排序查看时间日期和时间,最新查看的查询位于顶部。
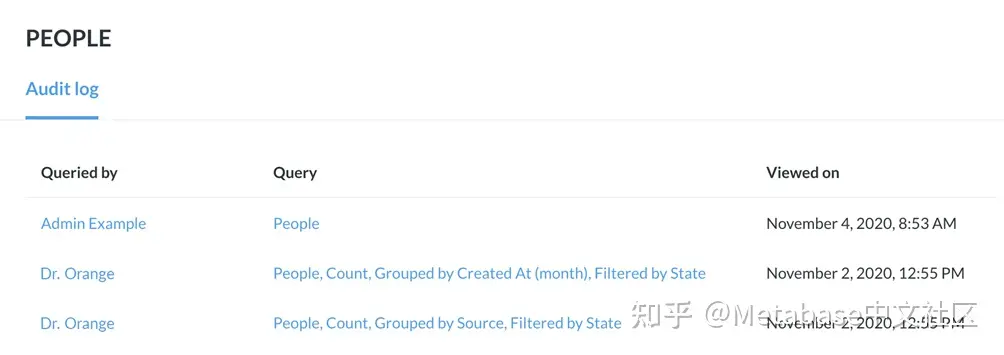
图3. People表审核日志。
从表audit log中,我们可以看到管理员不是唯一查看People表。如果Orange医生不能进入People表中,我们可以更深入地检查Orange博士的帐户,查看他们查看了哪些查询,撤销他们的访问权限数据权限,将Orange博士能够访问的集合中的任何任性查询归档,并与他们谈论他们所查看的数据。
请注意,如果有人使用本机查询(就像SQL语言问题)访问人桌子,我们在这里看不到。Metabase可以知道的关于本机查询的是它所查询的数据库,因此我们必须单独检查每个查询。因此,请注意您添加到具有数据库SQL查询访问权限的组中的人员。
Brown女士最近看到了什么?
Brown女士最近辞职了,我们想检查一下她在工作的最后一周查看了哪些数据。要查看人们查看的数据,我们将使用审核侧边栏在左边选择团队成员这让我们很好地了解谁是最活跃的Metabase用户(图4)。
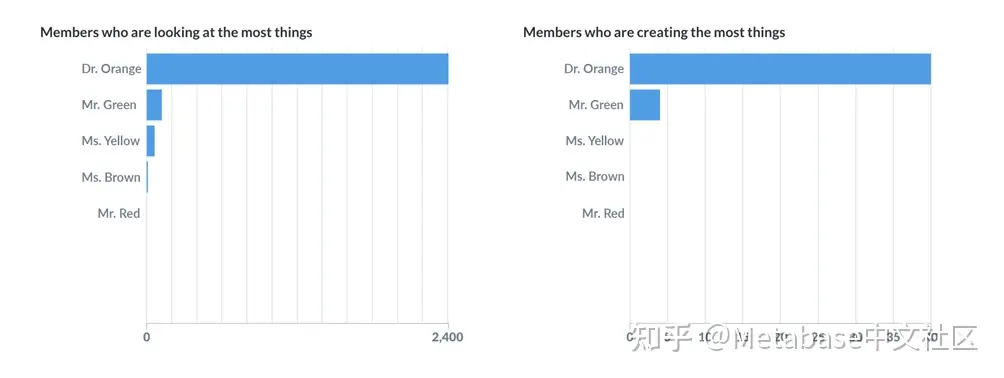
图4. “工作组成员”选项卡.
要查看Brown女士的活动,请单击所有成员选项卡。成员列表包括每个用户的名称、组、加入日期、上次活动日期和注册方法。
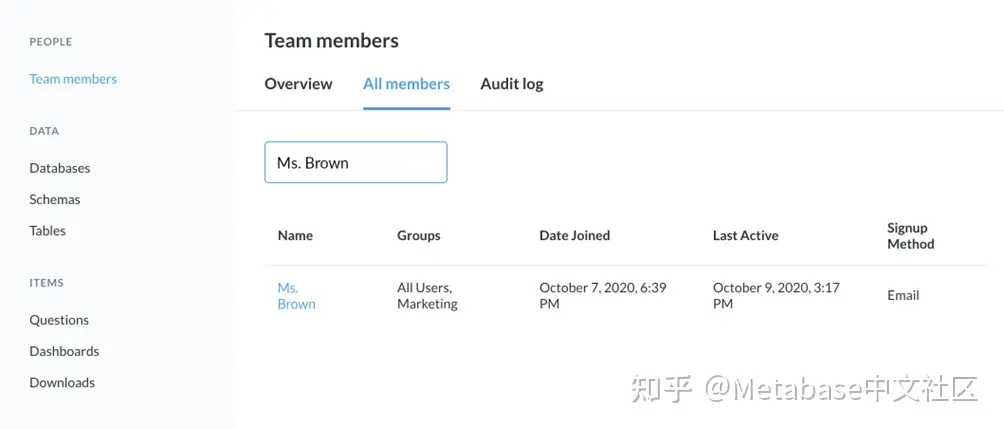
图5 Green女士的出现,是“先生”的唯一结果。Brown的搜索。
我们将单击Brown女士的名字,深入查看有关她在Metabase中的操作的详细信息(图6)。用户页面显示用户的活动亮点、查询视图、仪表板视图和下载的项目。
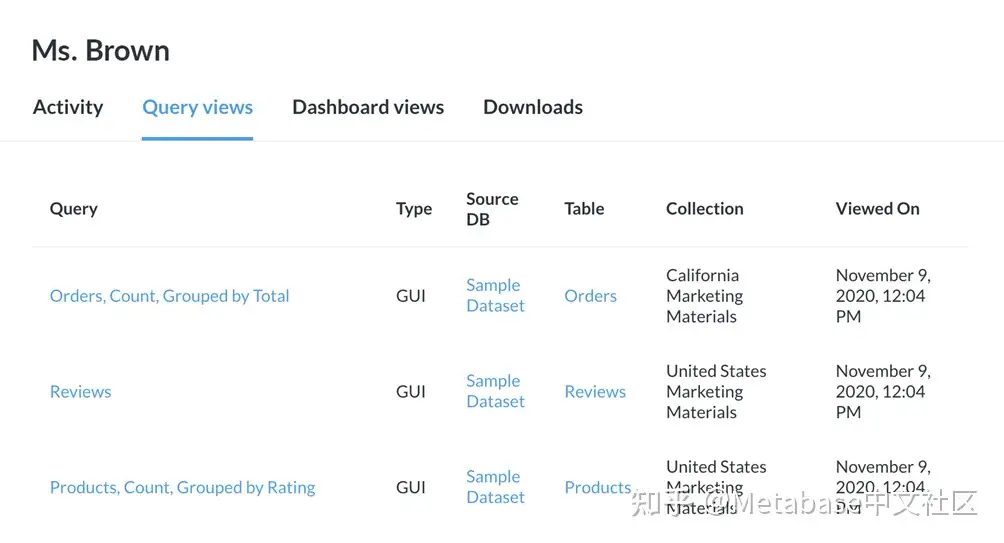
图6 Brown女士的特定审计页面打开到“查询视图”选项卡。
用户下载了多少数据?
我们去下载然后看看“概述”选项卡。从第一个图表(图7)中,我们可以看到只下载了四个问题。从左下角的图表中,我们可以看到哪些用户下载了这些数据。
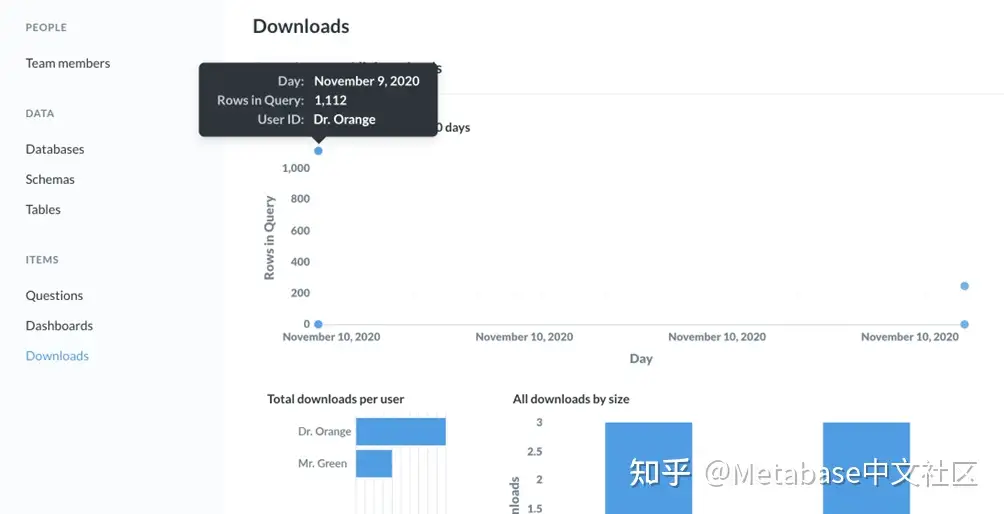
图7. “概述”选项卡对于下载显示三个图形的部分。
Orange博士的一个下载量相当大(至少对于示例数据库而言):1112行数据。单击所有下载选项卡看看Orange博士下载了多少行。
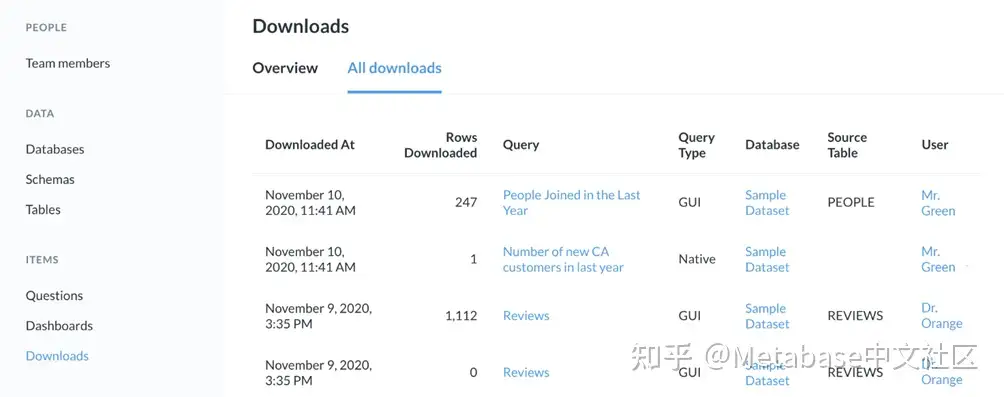
图8. 下载审核日志。
在列表的顶部我们可以看到Orange博士的下载是一个名为Reviews的查询。如果我们需要更多信息,我们可以点击问题并选择在Metabase中打开.
图9。将鼠标悬停在在Metabase中打开屏幕顶部的按钮。
优化我们的Metabase实例
我们还可以使用审计日志来寻找机会,使我们的仪表板加载更快,或者通过确保人们使用他们可以信任的仪表板来帮助人们找到他们需要的数据。
为什么CA营销仪表板加载缓慢?
我们假设有人抱怨CA营销仪表板加载时间慢。在审核侧边栏的数据库节中,我们可以看到查询总数及其平均运行时间的摘要。
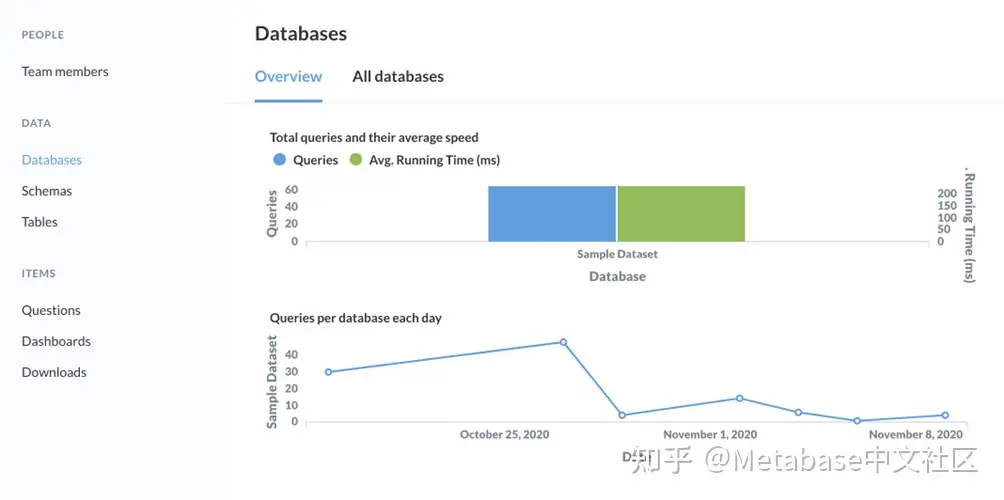
图10。数据库概述选项卡和此处显示的两个图形。
示例数据库的加载时间不到一秒,因此我们知道数据库总体上不会减慢任何速度。可能是仪表板本身的加载问题?
我们去审计分区并选择CA营销仪表板从最流行的仪表板图表。在仪表板的个性化页面中,我们可以看到这个仪表板确实需要一段时间来加载,因此我们将单击修订历史选项卡查看人们对仪表板所做的可能影响加载时间的更改。
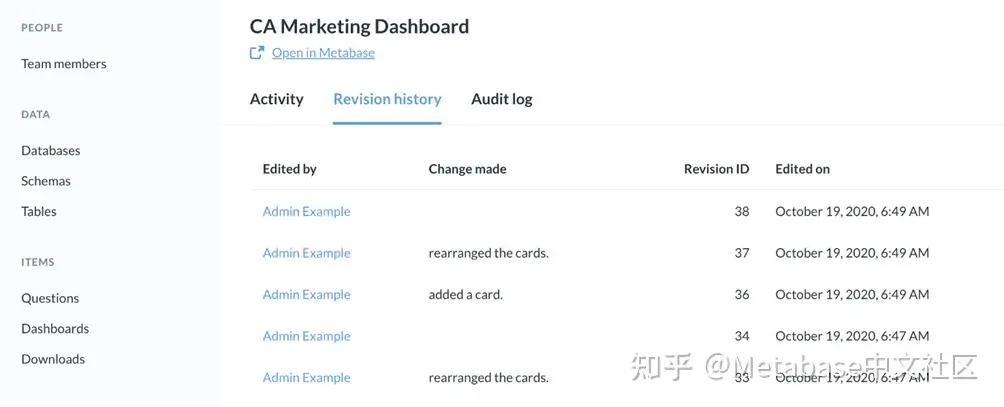
图11. CA营销仪表板修订历史选项卡。
在这里我们可以看到一个用户最近在仪表板中添加了一张卡。这张卡片可能是减慢仪表板速度的原因。
强化重要用户访问?
假设我们最近锁定了一个关键问题,重要用户,并想看看固定它是否有助于推动问题的流量。在问题部门“概述”选项卡,我们将看到两个图表:最流行的查询和加载最慢的查询。
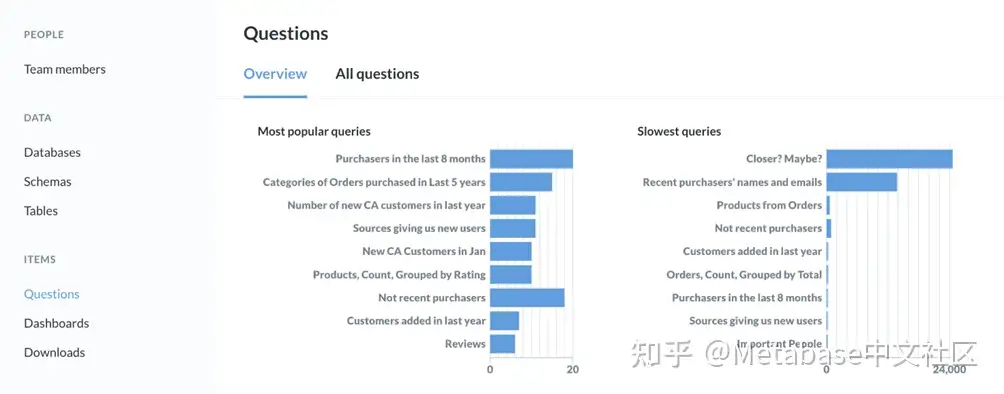
图12. “概述”选项卡.
要查找特定问题,我们将打开所有问题选项卡然后选择重要用户从名单上。
我们固定的这个问题收集十月下旬。我们可以从图表中看到活动选项卡这种固定有助于让人们了解我们的仪表板。
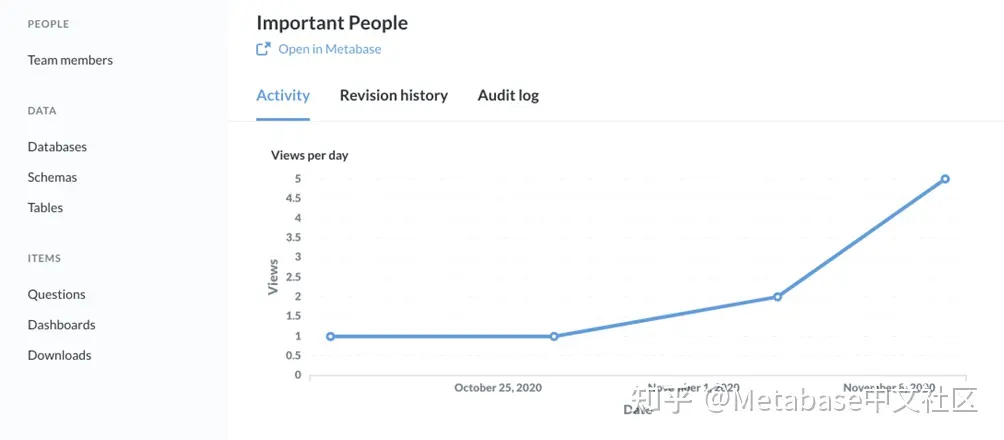
图13。重要用户问题特定页面。 -
Metabase学习教程:系统管理-11 数据沙盒发布在 Metabase学习教程
数据沙盒:设置行级别权限
了解如何使用Metabase的数据沙盒功能设置行级别权限。
Metabase商业版本包括数据沙盒,这一功能使您能够精确控制人们可以访问的数据,从整个数据库到特定的数据库列和行。
“沙盒”通常指创建一个用于保护或隔离系统的一部分的隔离环境。Metabase以类似的方式使用术语沙盒,但在本例中,独立环境指的是“数据环境”。当管理员授予组沙盒访问表的权限时,他们只能看到沙盒中包含的行和列。
在本文中,我们将介绍一个包括在Metabase中使用的示例数据库。数据沙盒可以限制对列和行的访问。我们将在本文中介绍行级别的权限;有关列级权限,请参阅高级数据沙盒.
在使用沙盒之前
你应该退后您的Metabase应用程序数据。此外,您还可以查看我们的数据权限指南,收藏权限指南,以及我们的权限概述为了更好地了解沙盒如何与Metabase的权限系统相适应。
我们的设想
我们的目标是确保客户Brown女士只能看到与其帐户相关的表行。
创建客户组
Metabase使用组来组织权限,因此我们首先需要创建组,我们称之为顾客。要执行此操作,请单击齿轮图标在导航侧栏中,选择>管理员设置>用户>组。然后选择创建组.
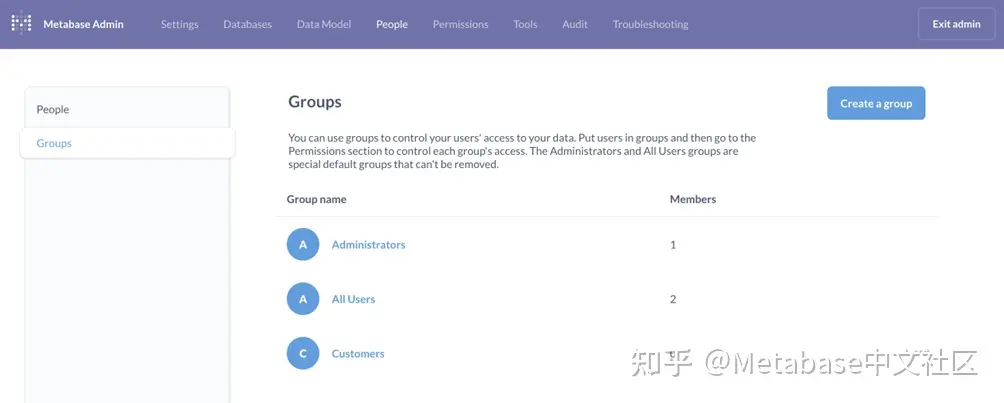
图1。创建客户组后的“组”页。
创建帐户并添加属性
在为Customers组设置沙盒权限之前,我们需要创建帐户给Brown女士,她的账户加上属性。从管理员设置>人,我们点击邀请某人,填写姓名和电子邮件字段,并将她添加到客户组。
这里是沙盒的重要部分:我们将为我们的新人Brown女士添加一个属性,其键为user_id值20.
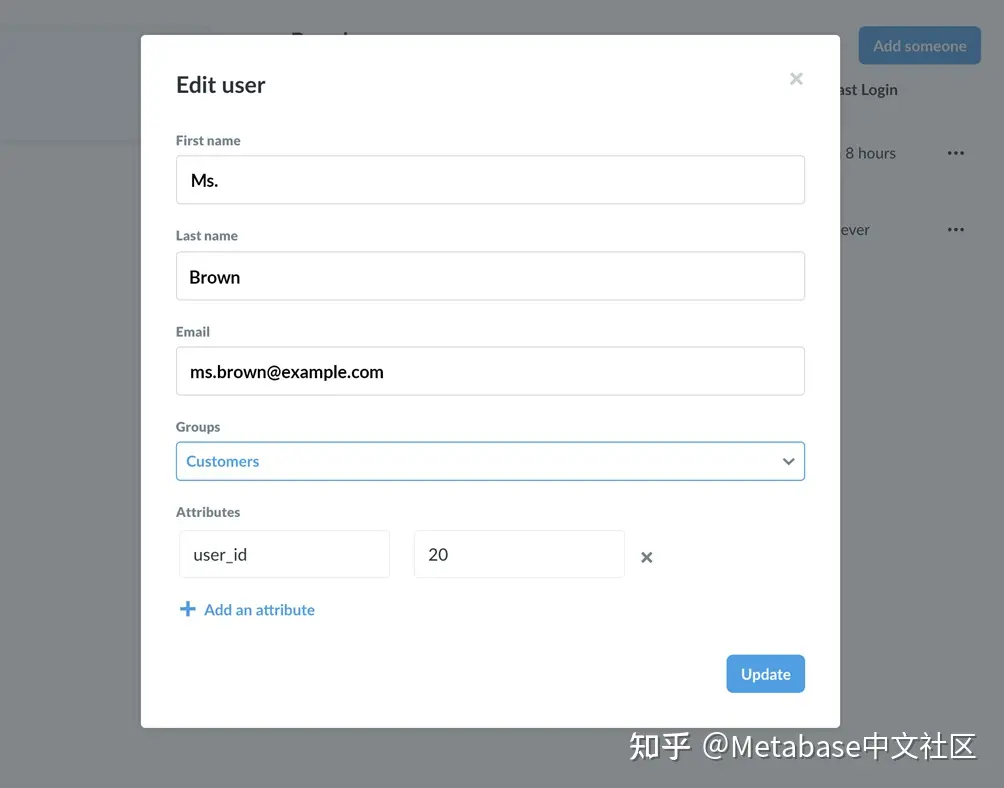
图2.将Brown女士添加到客户组,并赋予她一个属性:user_id:20。
没有什么神奇的user_id凯:这只是一个变量。我们可以使用我们选择的任何键值对添加属性。我们想要的是对要沙盒的相关表使用与列对应的键和与行值相对应的值。我们的想法是将这个属性链接到表中的一列,以确定Brown女士可以查看哪些行。
出于本演练的目的,我们手动设置此属性,但我们可以使用单一登录服务(SSO),比如SAML以编程方式向用户分配和同步属性。
授予组沙盒访问权限
现在我们有了我们的小组,而且至少有一个小组成员有一个属性(Brown女士),我们准备前往数据权限页授予客户组沙盒访问示例数据库中表的权限。
在左侧边栏中,我们将单击数据库和示例数据库。授予客户组沙盒访问命令表,我们只需点击命令表,导航到Customers行并选择沙盒从下拉菜单。
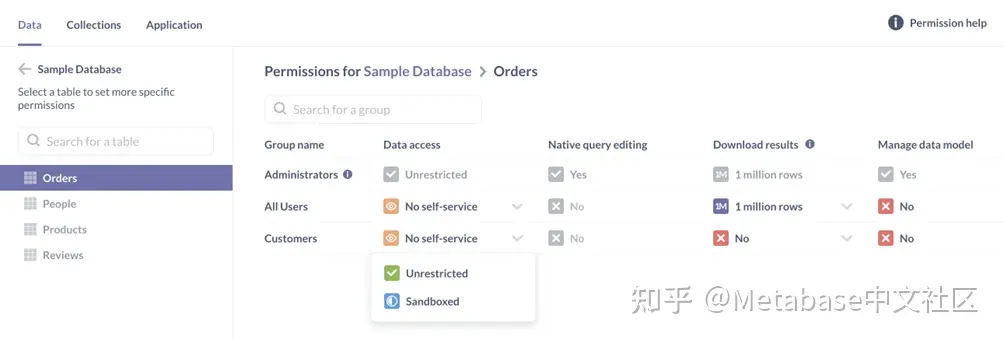
图3。正在授予对Orders表的客户组的沙盒访问权限。
这个沙盒模式将询问“您希望如何为该组中的用户筛选此表?”并提供两种选择:
• 过滤器按表中的一列。
• 使用保存的问题为该表创建自定义视图。
现在,我们将设置为按表中的列筛选-使用保存的问题是一个更高级的功能,我们将对此进行讨论在这里.
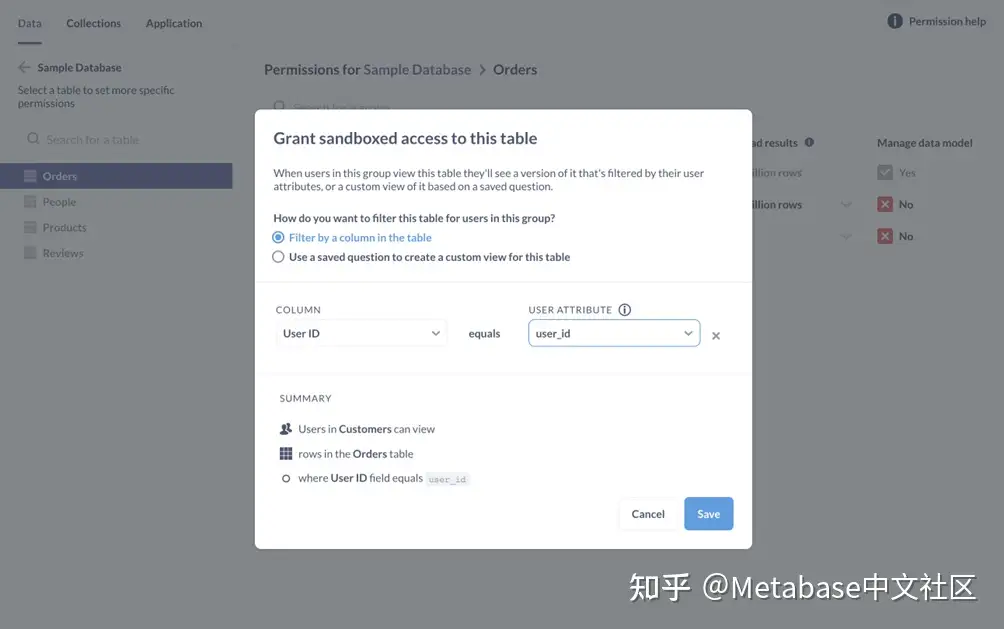
图4. 沙盒模式.
对于列,我们将选择user_id的列命令表,然后我们将其连接到user_id属性从我们分配给人的属性的下拉菜单。
Metabase将为我们提供所做更改的摘要:“客户中的用户可以查看Orders桌子在哪里user_id字段等于user_id “让我们保存我们的更改并为人表。
• 为的客户组授予沙盒访问权限People表。
• 选择按列筛选选项。
• 选择ID的列人把它连接到user_id属性。
• 查看摘要并单击“保存”。
最后,我们需要单击保存更改按钮确认我们的更改。
检查设置,因为Brown女士看到了世界
现在让我们测试一下我们的设置,以确认我们的客户Brown女士只能看到与她的用户ID相关的订单。我们将在匿名浏览器窗口中打开Metabase实例,并以Brown女士的身份登录。当我们导航到Orders表,Brown女士只能看到她下的订单(用户ID 20)。
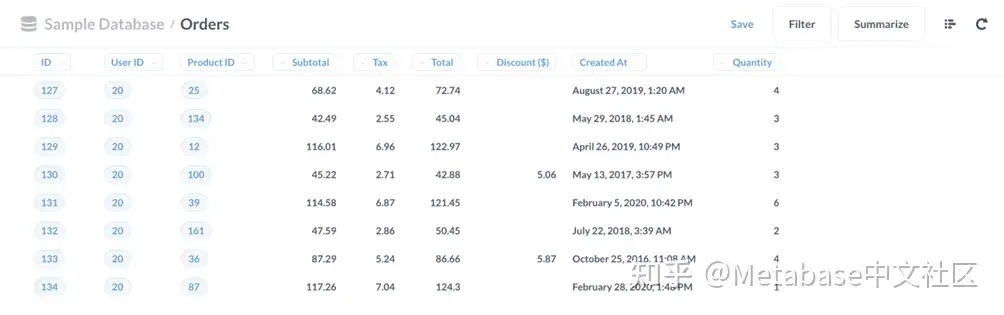
图5Brown女士只能看到与她ID20相关的订单。
通过沙盒化表格,我们可以创建一个问题或仪表板,请放心,具有沙盒访问该数据的用户将只能看到与其帐户关联的数据。
如果我们将沙盒与完整应用嵌入,我们可以将这些仪表板嵌入到我们的应用程序中,并使用SSO将属性传递给嵌入的Metabase实例,从而允许我们提供对嵌入在应用程序中的问题和仪表板的沙盒访问。要了解更多信息,请参见如何在应用程序中嵌入Metabase以提供多租户、自助服务分析.
沙盒限制
• 沙盒仅适用于SQL数据库。
• 一个用户每个表只能有一个沙盒,因此只能将用户添加到具有沙盒访问权限的单个组中。
• 如果一个组具有对数据库的SQL查询访问权限,则沙盒无法阻止该组中的人员查看这些表中的数据。
• 通过扩展,如果该组中的人员可以访问用SQL编写的问题,那么这些问题将不知道沙盒访问权限,并将向该组中的人员显示所有结果,而不仅仅是该组沙盒中的结果。
进一步了解数据沙盒的局限性.高级数据沙盒:限制对列的访问
了解如何使用已保存的SQL查询对表进行沙盒处理,并根据用户属性限制用户可以查看的列。
我们的文章行权限涵盖了沙盒(商业版本). 我们将沙盒定义为一种根据用户身份指定用户可以访问哪些数据的方法,并向您展示了如何限制对表行的访问。例如,我们创建了一个用户Brown女士,并让她访问People和Orders和她相配的数据表user_id属性。
在本文中,我们将介绍如何对Products限制表Brown女士可以看的行和列。在这种情况下,我们希望Brown女士:
• 只在Products表。
• 只看到Title, Category, 和 Price列(而不是任何其他列)。
计划
我们要:- 创建只有管理员才能访问的集合。
- 创建新的SQL查询。这个Products表不包含有关用户的信息。所以为了限制Brown女士接触Products我们得查一下Brown女士订了哪些产品。我们会写一个SQL语言从中组合数据的查询Products表中的数据来自Orders表。在组合这些表时,我们将创建一个只包含所需列的新表格结果。
- 沙盒Products表中显示查询结果,而不是Brown女士的原始表。
- 通过验证Brown女士能看到的数据来确认我们的沙盒。
创建仅由管理员访问的集合
我们要创建一个集合存储将用于沙盒此表的SQL查询。就这么说吧沙盒问题并设置此集合的权限,以便只有管理员可以管理其问题。这样,非管理员就无法修改问题和更改沙盒的“维度”,例如通过包含Brown女士不应该看到的列。看到了吗集合权限了解有关设置权限的详细信息。
创建SQL查询
在顶部栏中,单击+新的>SQL查询到询问SQL问题。选择示例数据库包括在元数据库中。
下面是要粘贴到编辑器中的查询:
SELECT DISTINCT PRODUCTS.TITLE,
PRODUCTS.CATEGORY,
PRODUCTS.PRICE
FROM PRODUCTS
LEFT JOIN ORDERS ON ORDERS.PRODUCT_ID=PRODUCTS.ID
[[WHERE ORDERS.USER_ID IN ({{sandbox}})]]
查询的作用如下:
• 返回包含来自的列的结果Products表格:Title,Category, 和 Price.
• 检查产品是否不同,即每个产品只有一行。
• 可选过滤器此列表仅显示沙盒用户订购的产品。
双方括号[[…]]周围WHERE子句使子句成为可选的。双大括号{{sandbox}}定义变量。我们用这个{{sandbox}}在沙盒中处理此问题时变量。
让我们运行查询,结果如下:
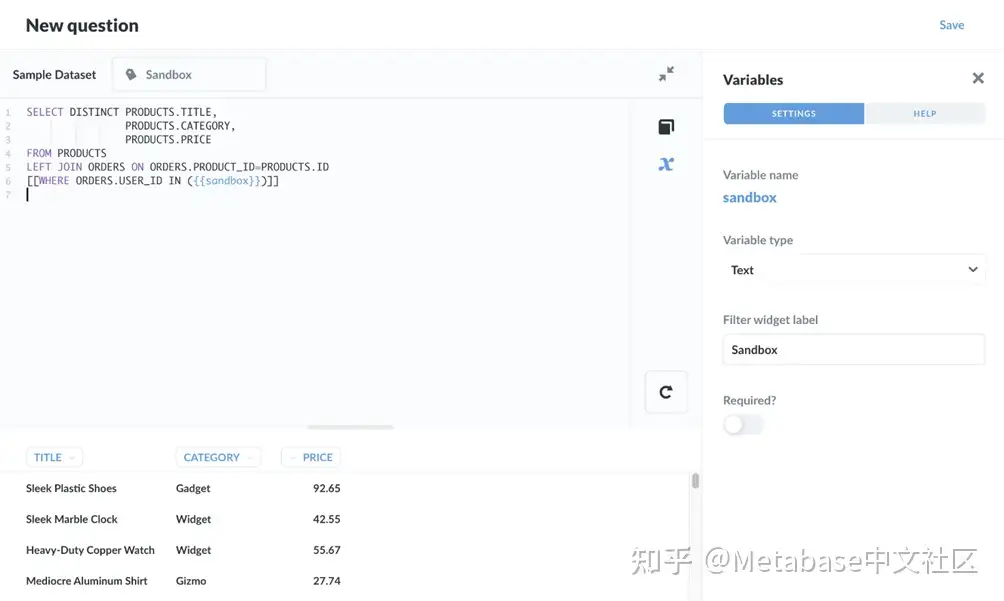
图1.SQL查询以创建新表。
现在我们把这个问题另存为订单中的产品,存储在沙盒问题我们创建的集合,并选择不将问题添加到仪表板.
这里需要重申一点:我们只从Products表,因为我们的查询应该只返回要沙盒的表中的列。
使用我们保存的问题对Products表进行沙盒处理
现在我们已经创建了订单中的产品问题,是时候把Products表。我们将设置沙盒,以便元数据库插入user_id我们在关于行权限进入{{sandbox}}我们保存的SQL问题中的变量,订单中的产品.
我们点击齿轮图标,选择管理员设置,然后单击权限标签。在左边,下面数据库,我们将单击示例数据库和Products因为Brown女士是客户组的成员,而且是元数据库的成员向组授予数据权限,而不是个人,我们将授予客户沙盒访问Products表。
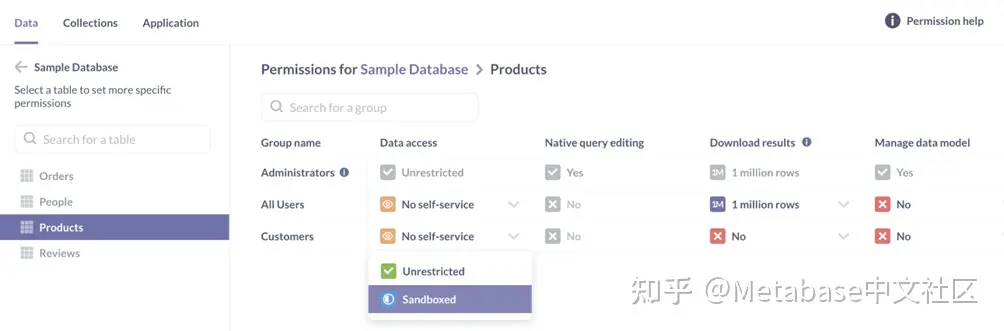
图2。授予客户组沙盒访问Products表。
当Metabase弹出沙盒模式,在“您希望如何筛选此表以供此组使用?”节中,我们将选择第二个过滤器选项:“使用保存的问题创建此表的自定义视图。”
我们将只导航到管理员沙盒问题收集并选择我们的问题,订单中的产品.为参数或变量,我们将选择SQL查询中包含的变量,{{sandbox}}.为了用户属性,我们将选择user_id.
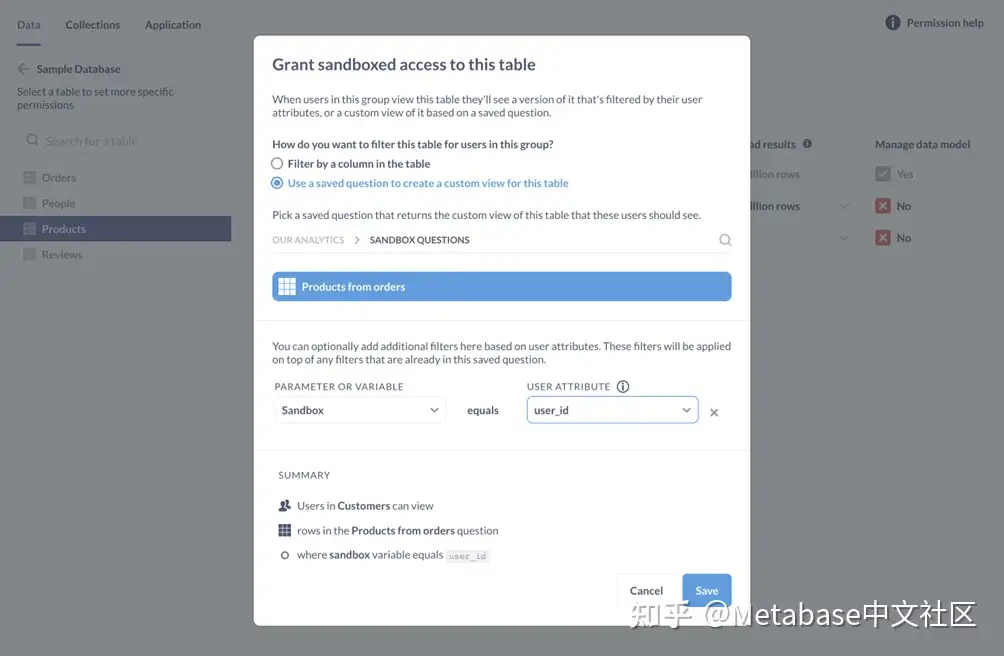
图3. 沙盒模式总结了我们选择的效果。
我们的总结是:
• 客户群中的人员
• 可以查看订单中的产品问题
• 在哪里沙盒变量的值等于user_id
让我们点击保存在模态中,然后单击保存更改在公告栏里。
以沙盒用户身份检查设置
让我们看看我们的沙盒Products从Brown女士的角度看,这张桌子很像。打开一个私人浏览器窗口,导航到我们的元数据库,然后以Brown女士的身份登录。
当我们打开Products使用数据浏览器,我们可以确认,Brown女士只能看到她订购的产品的列表,并且只有我们保存的三列订单中的产品问题:Title,Category, 和 Price.
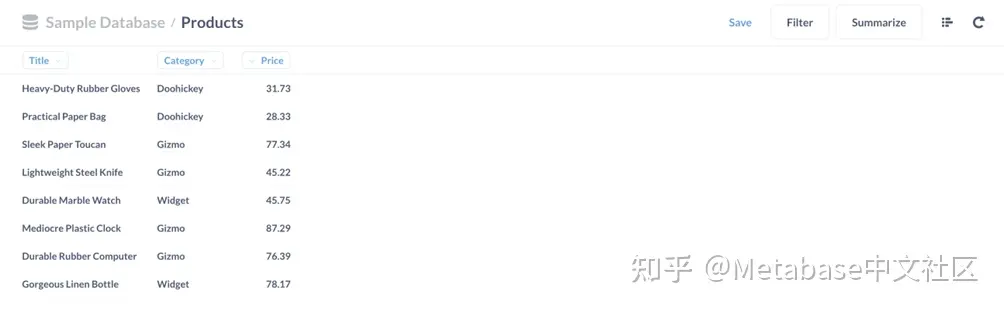
图4. ProductsMetabase主页上的表格只显示了Brown女士订购的产品。
如果Brown女士问的问题Products表,她仍然只能看到基于她订购的产品的结果。如果她可以访问包含沙盒外部列的问题,她将看到一个错误。
在对表进行沙盒处理时,更喜欢使用SQL问题
当我们可以使用GUI问题为了沙盒化一个表,我们建议改用SQL问题。在后台,自定义问题基于过滤器,摘要,和加入在我们的定制问题中。当我们基于一个定制问题进行沙盒测试时,我们可能没有意识到我们提供给人们访问的信息的全部范围。
或者,我们可以使用查询编辑器创建一个自定义问题,然后在引擎盖下查看SQL代码元数据库将运行。在笔记本编辑器中,我们可以单击查看SQL按钮,以确认元数据库包含正确的表和列,而不包含其他内容。
扼要重述
当用沙盒回答问题时:
• 更喜欢SQL查询.
• 确保保存的问题只返回要沙盒的表中的列。
• 将沙盒问题保存在非管理员无法访问的集合中,最好是专门用于沙盒问题的集合。
-
Metabase学习教程:系统管理-10 集合权限发布在 Metabase学习教程
使用集合权限
设置具有权限的集合,以帮助用户组织和共享与其相关的工作。
集合保持问题,仪表板,和模型有条理,容易找到。将集合视为存储我们工作的文件夹是很有帮助的。集合权限授予一群人访问:
• 查看或编辑保存在集合中的问题、仪表板或模型。
• 编辑集合详细信息,例如集合的名称或保存位置。
在本教程中,我们将为一家拥有名为Canoes和Sailboats的团队的公司创建集合,并设置收集权限,以便:
• 公司中的每个人都可以查看但不能编辑保存在公司顶层集合中的工作(在Metabase中,它被称为我们的分析-您可以将其视为根目录或父文件夹)。
• Canoes团队中的人员可以保存、查看和编辑Canoes集合中团队成员之间共享的工作。Sailboats队的人将获得他们自己的Sailboats集合。
• Canoes小组将只能查看保存在Sailboats集合中的作品。Sailboats队只能观看Canoes集合。
查看默认集合权限
在一个全新的代谢数据库中:- 单击装备图标然后选择管理员设置>权限>集合.
- 点击我们的分析转到根集合的“集合权限”页。
从我们的分析权限页面,你会找到的收集访问设置为Curate对于默认组管理员和所有用户。
所有用户包括添加到您的Metabase的所有用户,以及Curate权限允许组查看和编辑集合。因此,Metabase的默认收集权限将允许船上的每个人查看和编辑保存在中的工作我们的分析.
配置“我们的分析”权限
我们要撤销对我们的分析,因为Metabase授予最宽容的对某人所属的所有组的访问级别。
您无法从“所有用户”组中删除人员,因此如果您将Curate权限我们的分析,那么对于使用你的Metabase的每个人来说,这永远是最宽松的设置,而不管你把其他人放在哪个组中。 - 去管理员设置>权限>集合>我们的分析.
- 单击所有用户行和收集访问列(图2)。
- 选择禁止进入。打开同时更改子集合以便这些权限应用于嵌套在我们的分析.
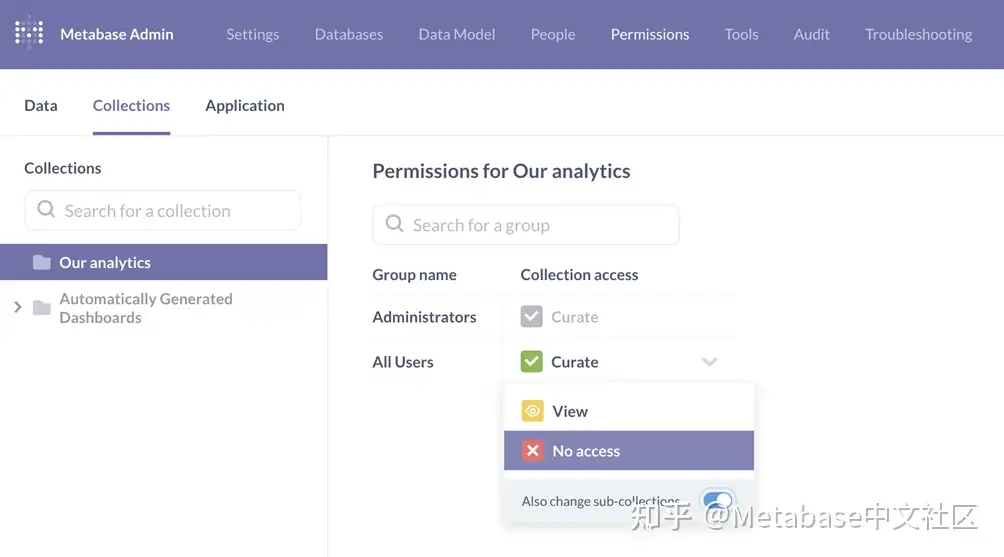
图1。取消所有用户对我们的分析集合及其子集合的访问权限。
创建新组和集合
接下来,我们将创建组来匹配我们的Canoes和Sailboats队。去管理员设置>人>组>创建组,并称之为“Canoes”。
要创建新集合,我们将转到Metabase主页并单击+新的>集合。我们将创建两个名为在我们的新团队之后,并将这些集合保存在其中我们的分析.
设置集合权限
我们将首先为Canoes集合设置集合权限,以便:
• Canoes组可以查看和编辑Canoes集合中保存的问题、仪表板和模型。
• Canoes组可以移动、重新命名或存档Canoes集合。
• Sailboats组只能查看保存在Canoes集合中的工作。
您可以导航回管理员设置然后转到每个集合的集合权限页面,或者可以直接从Metabase主页设置权限(图2): - 单击侧栏中的Canoes集合。
- 单击锁定图标打开集合权限模式。
- 选择Curate从下拉菜单Canoes行和收集访问列(图3)。
- 选择视图从下拉菜单Sailboats行和收集访问列(图3)。
- 点击保存.

图2。向Canoes集合授予不同的权限。
设置的权限Sailboats所以Sailboats组Curate访问,但Canoes组具有“仅查看”访问权限: - 单击Sailboats侧边栏中的集合。
- 单击锁定图标打开集合权限模式。
- 选择Curate从下拉菜单Sailboats行和收集访问列(图3)。
- 选择视图从下拉菜单Canoes行和收集访问列(图3)。
- 点击保存.
集合权限如何与数据权限交互
集合权限 数据权限
查看结果保存在给定集合中的问题、仪表板或模型。 查看和查询问题、仪表板或模型使用的底层表。
假设我们的Canoes组有两组权限:
• CurateCanoes集合的集合权限。
• 无自助服务的数据权限Orders表。
如果Canoes集合包含使用Orders表(图4),您可以期望每个权限允许Canoes组执行以下操作:
CurateCanoes系列 无自助服务到Orders
编辑问题标题或描述。 查看问题的可视化(“结果”)。
将问题移动或复制到其他集合。 更改问题返回的现有结果的可视化类型。
基本上,Canoes小组将能够与保存在他们的集合中的问题进行交互,但是他们不能从表格(无论是通过问题还是通过数据浏览器)。
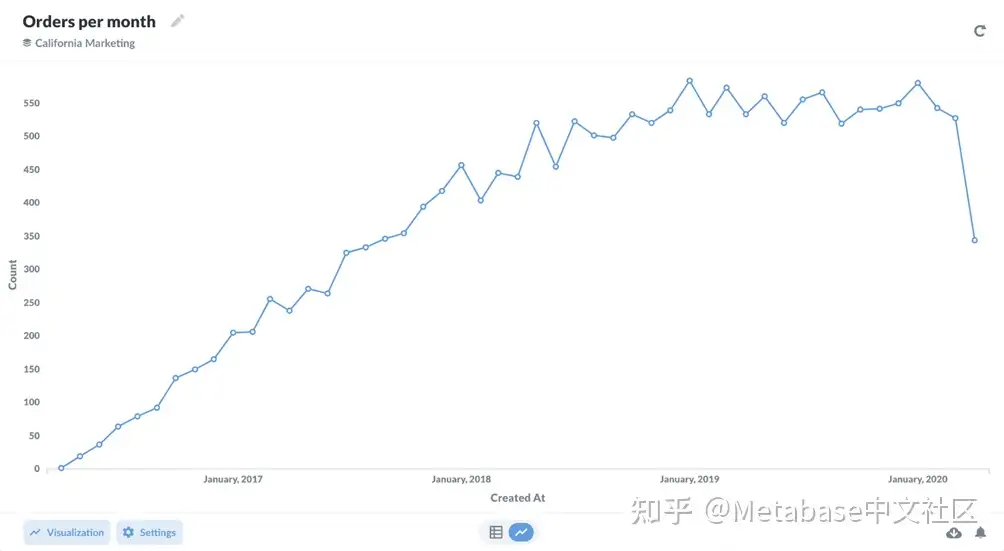
图3。查看保存在对问题数据没有自助服务权限的可访问集合中的问题。
从更改Canoes组的数据权限无自助服务到不受限制将更新选项,以便Canoes组可以:
• 使用查询生成器更改问题使用的查询。
• 从中筛选或汇总数据Orders表更新问题返回的结果。
• 查看Orders表来自问题名称下方的链接。
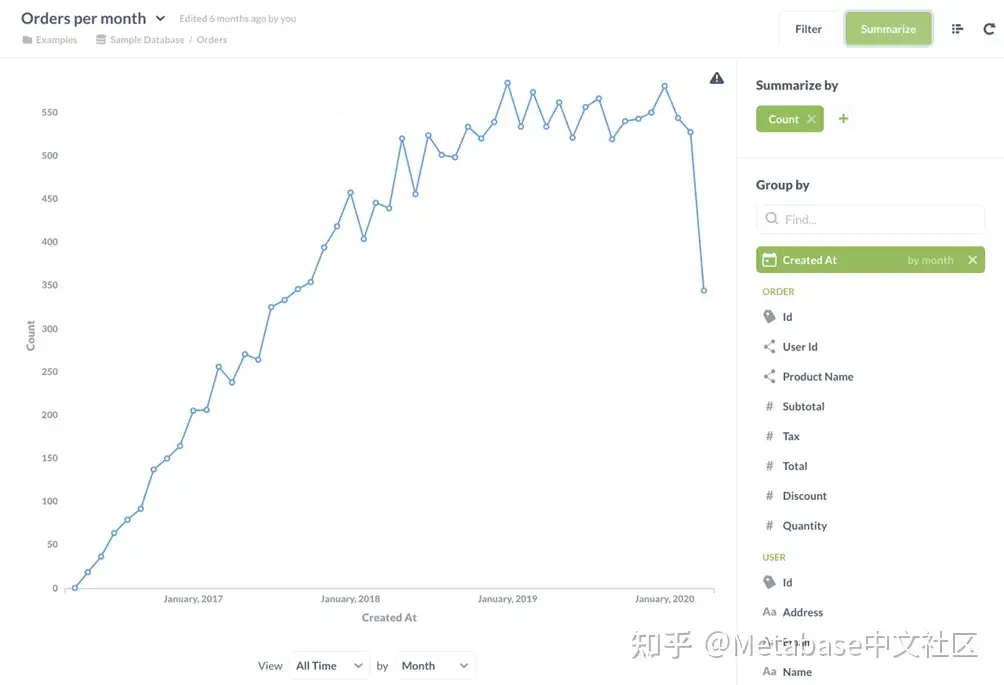
图4。查看保存在对问题数据具有不受限制权限的可访问集合中的问题。
权限如何应用于包含来自不同集合的问题的仪表板
假设Canoes组拥有一组更新的权限:
• CurateCanoes集合的集合权限。
• 禁止进入收集Sailboats集合的权限。
• 不受限制的数据权限Orders表。
如果仪表板上的所有问题也保存在Canoes集合中,Canoes组将看到所有卡片:
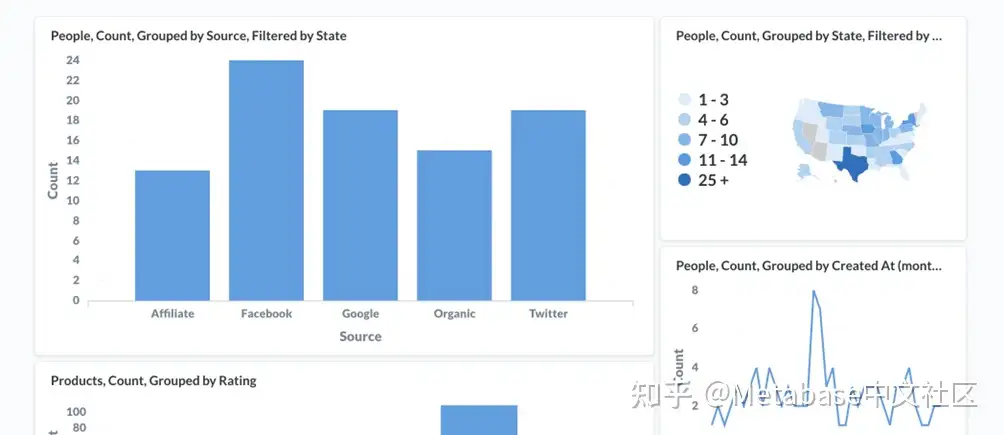
图5。查看包含保存在可访问集合中的问题的仪表板。
如果仪表板上的某个问题保存在Sailboats集合中(即使该问题使用Orders表),Canoes小组将看到一张“锁定”卡片:
图6。查看由保存在不可访问集合中的问题导致的锁定卡的仪表板。
由于非管理员不知道组或权限,因此当具有更广泛权限的用户尝试与具有更严格权限的用户共享工作时,可能会出现“锁定”卡。
例如,假设海盗船组织有权从Canoes和Sailboats集合中帮助自己。如果海盗船组建立了一个仪表板并与Canoes组成员共享,Canoes组成员将看到锁定的卡,任何问题仍然保存在Sailboats收集。
为避免卡被锁定,我们建议将问题复制到要保存仪表板的集合中。 -
Metabase学习教程:系统管理-9 数据权限发布在 Metabase学习教程
数据权限指南
通过设置对Metabase包含的示例数据库的权限,了解Metabase如何处理数据权限。
数据权限指定差异有多大一群人可以与表和数据库交互。在本文中,我们将介绍一个示例,说明如何授予用户从中查看、编辑或查询表的权限示例数据库.
引入数据权限
让我们从导航到行政>权限,然后选择数据库>示例数据库。这将转到数据库级别的“数据权限”页。如果要为每个数据表在Sample数据库中,可以单击左侧的表名。
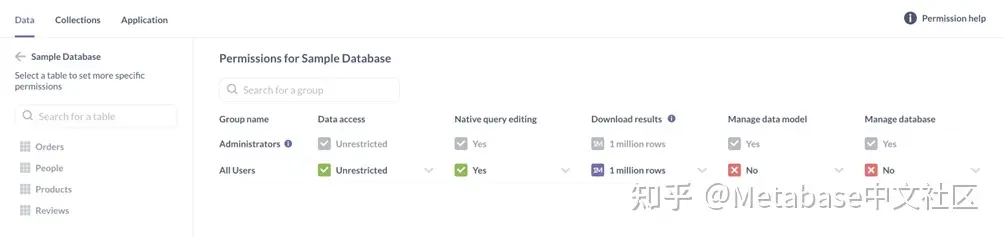
图1。在进行任何更改之前,请打开示例数据库的“数据权限”页。
必须为组配置数据权限.Metabase附带两个默认组:Administrators和All Users。我们将创建两个名为独木舟和帆船的新示例组,并将数据权限设置为:
• 调整所有用户的默认权限设置。
• 允许独木舟小组进入Orders数据表。
• 允许帆船组访问People和Products只有数据表。
这里,“访问表”意味着我们将允许小组从查询编辑器使用给定表中的数据。
如果你想让人们使用本机查询(SQL)编辑器,你需要配置不同的数据权限集.
为“所有用户”组配置权限
首先,我们将撤销不受限制所有用户都可以访问数据库,因为Metabase授予最宽容的对某人所属的所有组的访问级别。
你不能从“所有用户”组中删除任何人,因此如果你给所有用户不受限制对示例数据库的权限,那么这将始终是每个使用您的Metabase的人的权限最大的设置,而不管您将其他人放在哪个组中。- 去行政>权限>数据库>示例数据库.
- 单击所有用户行和数据存取列(图2)。
- 选择无自助服务.
- 点击保存更改在顶部出现的横幅中。
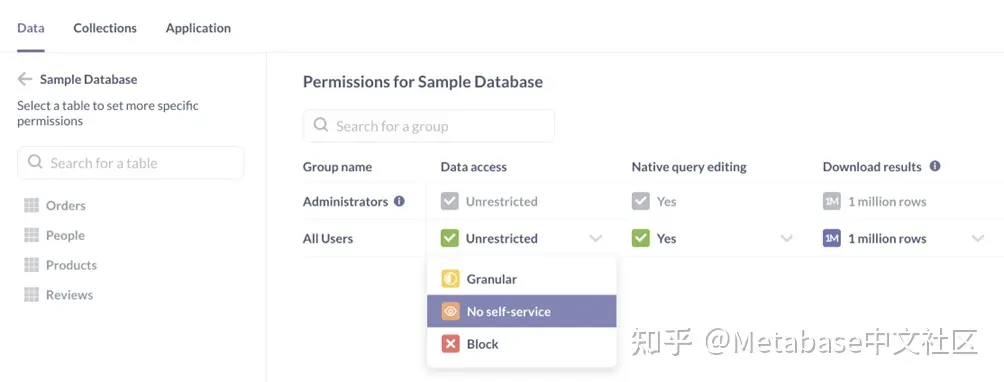
图2。选择“所有用户”组对示例数据库的“无自助服务”权限。
选择无自助服务对于所有用户,示例数据库将:
• 防止所有用户在中看到示例数据库中的任何数据数据浏览器.
• 阻止所有用户使用查询编辑器使用示例数据库中的数据创建问题。
• 继续允许所有用户查看结果(但不访问基础数据)来自使用示例数据库表的问题和仪表板,只要这些问题和仪表板保存在与集合权限为您的所有用户组。
配置本机查询编辑权限
正在从中更改所有用户的数据权限不受限制到无自助服务(在数据库级别)还将撤消所有用户对该数据库中每个表的本机查询编辑权限。取消本机查询编辑权限将:
• 防止每个人使用本机查询编辑器(也称为SQL编辑器)。
• 继续允许每个人查看使用SQL或其他查询语言创建的问题的结果,只要人们在组中使用正确的集合权限.
这里,“本机查询编辑权限”意味着我们将允许组像数据库IDE一样使用本机查询编辑器。将允许具有本机查询编辑权限的用户查询您的Metabase有权从数据库(由Metabase用于连接到数据库的角色定义)读取的所有数据。
有选择地授予本机查询编辑权限的最佳方法是创建一个单独的组(如“SQL用户”)。这群人需要不受限制使用本机查询编辑权限设置为“是”。有关详细信息,请参阅本机查询编辑权限.
创建用户组
让我们创建两个新的组,称之为独木舟和帆船。去行政>人。选择“组”选项卡,然后单击创建组。有关详细信息,请参阅创建组.
查看默认数据权限
去行政>权限>数据库然后选择示例数据库查看我们的新团队:
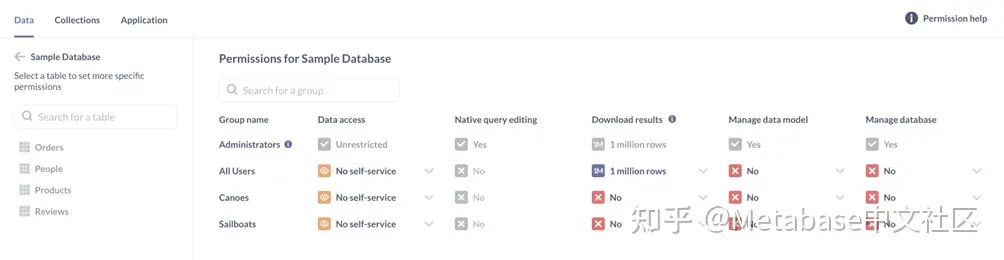
图3. 数据权限与我们新增加的独木舟和帆船小组。
新组默认为无自助服务权限。这使我们可以有选择地向每个组添加权限。
对于独木舟和帆船团体,无自助服务数据权限将:
• 防止独木舟和帆船上的人查看数据浏览器.
• 防止独木舟和帆船上的人使用查询编辑器在示例数据库表的顶部创建问题。
• 继续允许独木舟和帆船上的人查看基于示例数据库表构建的问题的结果,只要这些问题保存在与给定组匹配的集合中集合权限.
配置用户组的权限
允许独木舟小组进入Orders仅限表格: - 去行政>权限>组.
- 选择独木舟组。
- 点击示例数据库.
- 选择不受限制从下拉菜单中Orders行和数据存取列(图4)。
- 点击保存更改.
- 在出现的模式中,检查权限更改的效果,然后单击改变确认。
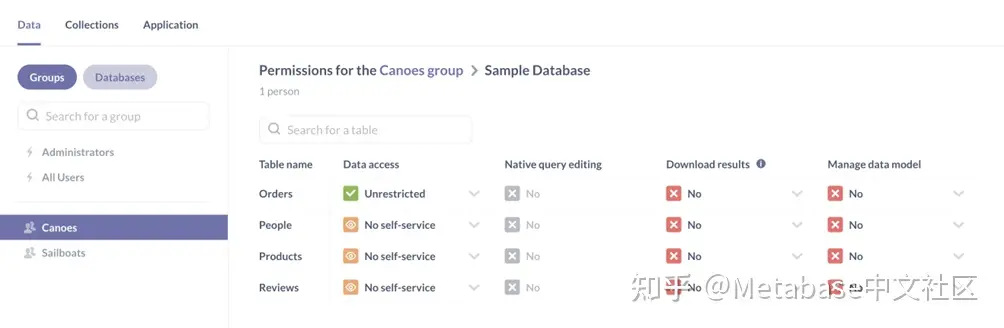
图4。授予独木舟组访问订单表的权限。
如果你点击进入独木舟集团在“独木舟组的权限”标题下,您将进入组级别的数据权限页。从那里,你会看到Metabase自动填充黄色颗粒状根据数据存取示例数据库的列。这个颗粒状权限表示Canoes组现在可以访问示例数据库中的一些表,但不是所有的表(图5)。
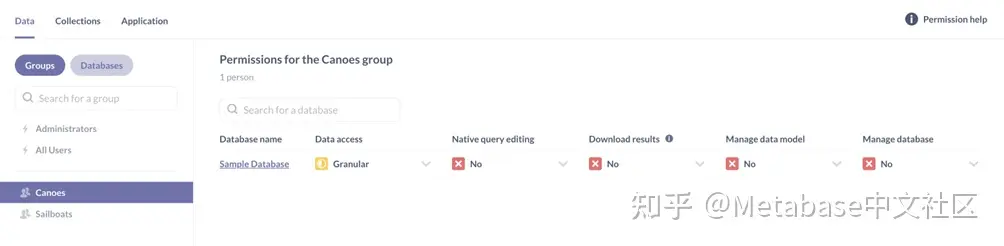
图5。独木舟组现在可以对示例数据库进行细粒度访问。
为多个组中的用户配置权限
让我们配置另一组数据权限以赋予帆船组不受限制的权限People和Products示例数据库中的表(图6):
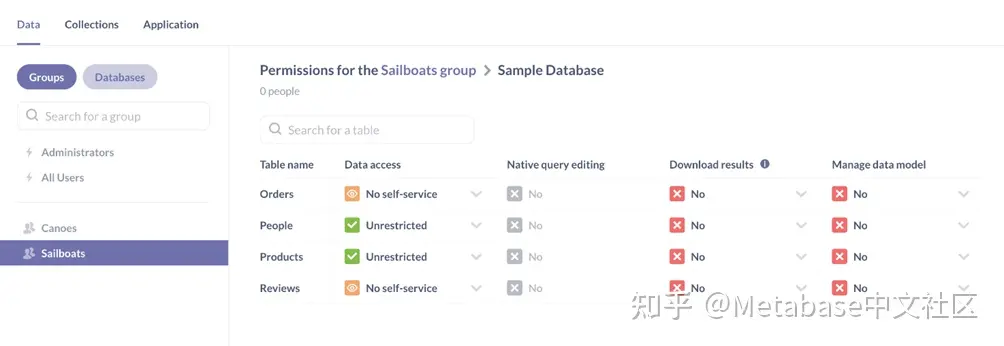
图6. 数据权限帆船组被授予访问人员和产品表的权限。
以下是我们当前数据权限的作用:
• 防止帆船组中的人使用Orders表。
• 防止独木舟小组的人使用People或Products数据表。
• 允许所有人(通过“所有用户”组)查看使用Orders,People,或Products表,考虑到它们有正确的集合权限.
假设船长先生同时属于独木舟组和帆船组,因此他有三组权限,这些权限来自三个不同的组:
• 无自助服务“所有用户”组对示例数据库的权限。
• 不受限制的权限Orders独木舟小组的数据表。
• 不受限制的权限People和Products帆船组的数据表。
由于Metabase在所有组中应用了最允许的设置,Captain先生将不受限制的权限Orders,People,和Products数据表。不受限制对这三个表的权限意味着Captain先生将能够:
• 使用查询编辑器的任意组合创建问题Orders,People,和Products.
• 钻取并操纵其他人的查询编辑器问题Orders,People,和Products,只要这些问题保存在与他匹配的集合中集合权限.
船长先生不属于不受限制的权限Reviews表或示例数据库,它将:
• 阻止他使用Reviews 表。
• 完全禁止他与本机查询编辑器交互(例如,查看、编辑或编写SQL查询)。
因为船长先生也是所有用户组的一员无自助服务对示例数据库的权限,他仍然可以查看使用Reviews表或本机查询编辑器,只要他有正确的集合权限。
更多数据权限选项
• 本机查询编辑.
• 下载结果*.
• 块.
• 管理数据模型*。看到了吗编辑元数据.
• 管理数据库*。看到了吗管理数据库(尽管只有管理员可以删除数据库)。
*仅适用于商业版本.
-
Metabase学习教程:系统管理-8 数据模型发布在 Metabase学习教程
Metabase中的模型
创建模型,为人们提供新问题的良好起始数据集。
为了让非技术人员更容易地询问有关您的数据的问题,您可以做的最有价值的事情是将您的数据放入一个使提问更直观的形状。
数据往往很混乱,尤其是对于初创企业。就算不凌乱,它可能是高度标准化数据针对事务而不是分析进行优化。这意味着您可以拥有一个数据库,其中客户的数据分布在大量的表中,这使得那些还不熟悉数据库的人很难找到他们要查找的信息(假设他们甚至知道).
模型作为构建块
为了使您的数据更直观,您可以创建问题,在查询生成器或者SQL编辑器,以在Metabase中创建派生表,调用模型,可以从不同的表中提取数据。您可以添加自定义列、计算列,并用元数据注释所有列,以便人们可以在查询生成器中将数据作为起点。
如果你已经是一个经验丰富的Metabase用户,你知道你可以从保存问题的结果。你可以把模型看作是一种特殊类型的保留问题,但这还不是模型的全部价值。
为什么不运行ETL作业在数据库中创建模型?
模型和ETL作业不是相互排斥的,各有各的作用,你可以(也应该)两者兼得。为了说明原因:- 模型将建模数据的工具交给了解业务领域的人。这是件大事。是的,数据工程师会更了解数据管道中的管道,但他们不一定知道特定团队面临的问题以及这些问题的各个部分应该如何定义(例如,什么才是活动用户?)。组织中的不同团队应该是定义您业务的团队,他们应该能够根据团队工作方式、新产品供应、市场变化等方面的变化来改进这些定义。有了模型,人们就不必经过数据团队来添加新的计算列或更新定义。不同的团队会有不同的定义:你的销售团队对于客户的模式可能与你的营销团队或成功团队不同。
- 模型是灵活的。你可以动态地创建模型,修改它们,切换它们——它们基本上只是查询+描述。他们是Metabase的一等公民,所以你可以把他们组织成集合,链接它们,并选择它们作为新问题的起点,或将它们添加到仪表板。您也可以将其存档,或将其更改回已保存的问题(尽管您会丢失元数据)。相比之下,etl的工作量要大得多,而且通常由了解数据管道、知道如何编写代码、调度作业等的人控制。有一些很好的工具可以帮助您编写etl,但对于需要灵活解决方案的问题,它们通常是一个重量级的解决方案。
- 模型是提高数据库性能的垫脚石。在Metabase中使用模型后,可以将最流行的模型“升级”成物化视图到你的数据库里。这里的物化意味着编写一个ETL作业,在数据库中创建并定期更新与模型匹配的表(具有相同的列集),这样就不需要每次运行查询时都计算结果;数据库可以像从原始数据表中获取结果一样。一旦在数据库中具体化了表,就可以用一个简单的SELECT FROM 物化模型,或者只删除模型并像对待数据库中的任何其他表一样对待物化表。(请注意,如果更改模型的基础查询,则需要更新每个列的元数据)。
典型例子
在考虑要在模型中包含哪些列时,最好先列出希望人们提出的问题类型,然后在模型中添加有助于回答这些问题的列。假设我们要为客户建模。通常情况下,我们可能需要定义活动客户,可能是在过去一个月至少访问过我们网站一次的人,或者无论如何,我们希望定义活动客户。但为了简单起见,我们将使用Metabase中包含的示例数据库为基本客户定义一个模型。我们希望了解客户的一些情况:
• 他们住的地方,包括州政府和邮编。
• 他们的来源(他们是如何发现我们的)。
• 他们和我们一起花了多少钱。
• 他们下了多少订单。
• 每个订单的平均总数。
在真实的模型中,您可能会有更多的问题需要回答,这将需要更多的列来回答(例如客户的年龄、他们在网站上花了多长时间、从购物车中添加和删除的项目,或者您认为您的团队将要问问题的所有其他数据点)。模型的想法是让所有的样板代码把所有这些数据聚集在一起,这样人们就可以开始玩他们真正感兴趣的数据了。
下面是我们的问题,使用查询生成器构建:
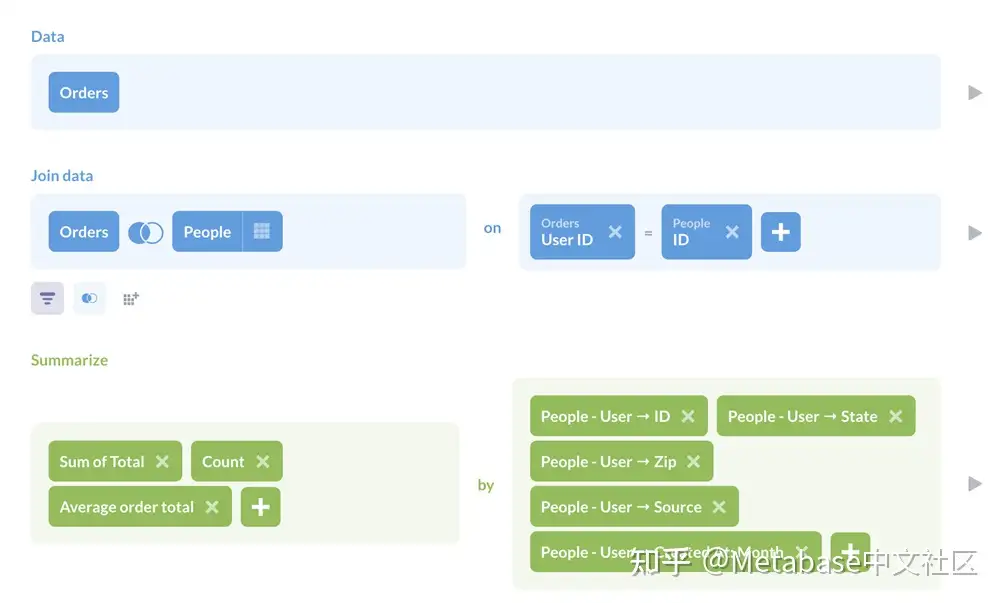
图1。查询编辑器中的查询。
对于我们的数据,我们选择Orders表,连接到People表中,汇总了订单总数的总和,计算了行数,并使用自定义表达式计算了平均订单总额:= Sum([Total]) / Count。接下来,我们按:User_ID, People.Created_At, State, Zip,和Source.
我们保存该问题,单击问题标题以显示问题侧栏(您可能需要刷新浏览器),然后单击模型图标(三个构建块堆叠在一个三角形中)将问题转换为模型。
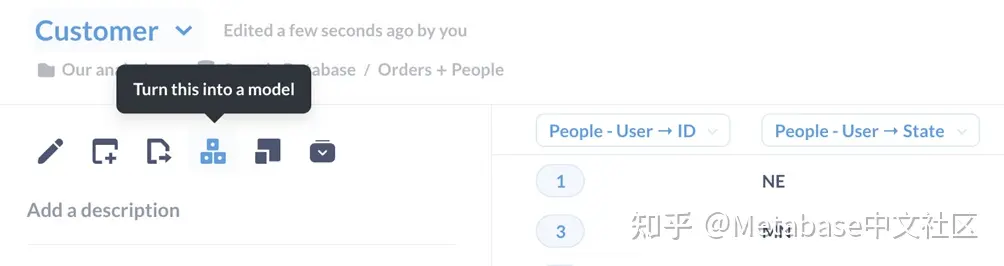
图2.将问题转化为模型。
向模型中添加元数据是关键
这是模型的超能力,对于使用SQL查询构建的模型特别有用,因为Metabase不知道SQL查询返回的列类型。
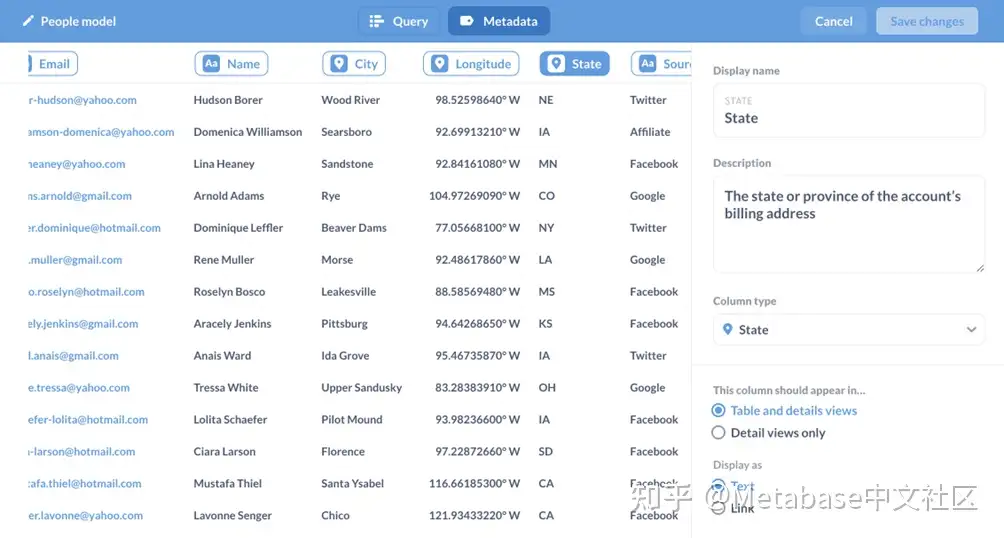
图3。重命名列,添加说明,并为每个列设置元数据。
单击模型的名称将显示模型侧栏,它为我们提供了自定义元数据。在这里,我们可以为列提供更友好的名称,向列添加描述(将在悬停时显示),并告诉Metabase该列包含的数据类型。
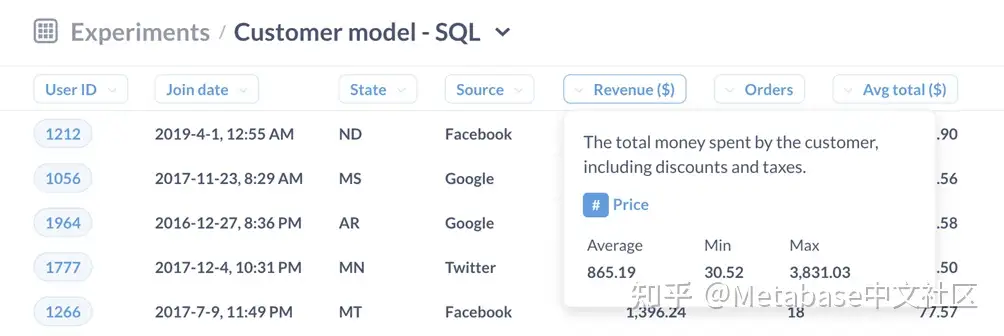
图4。将鼠标悬停在列上会触发带有列说明的弹出窗口。
如果我们使用SQL查询来创建相同的客户模型(请参见典型例子上图),如下所示:
SELECT
orders.user_id AS id,
people.created_at AS join_date,
people.state AS state,
people.source AS source,
Sum(orders.total) AS total,
Count() AS order_count,
Sum(orders.total)/Count(*) AS avg_total
FROM orders
LEFT JOIN people
ON orders.user_id = people.id
GROUP BY
id,
city,
state,
zip,
source
除非我们告诉Metabase结果中的每一列是什么类型的数据,否则Metabase将无法执行其通常的魔术。因此,一定要为每个列设置类型,以便Metabase能够在图表上显示操作菜单,并知道它应该为该列使用哪种筛选器(例如,数字筛选器对数字的选项与对日期或类别的选项不同)。
跳过SQL变量
这里有一个微妙的问题值得我们指出。如果你习惯用保存的问题和SQL变量(比如字段筛选器)为了让人们能够接受这些问题并将它们与仪表板过滤器联系起来,模型在这里采取了不同的方法。模型不处理变量,因为它们不需要。一旦告诉Metabase模型的列类型,就可以从该模型开始一个问题,保存它,并能够将其连接到仪表板筛选器。不需要在SQL代码中放入变量。
如果将模型添加到仪表板,您会注意到,即使在为这些过滤器设置了类型之后,也无法将其任何列映射到仪表板筛选器。要获得与模型相同的结果,您可以:
• 创建一个没有变量的模型。
• 根据模型保存问题。
• 将该问题添加到仪表板。
• 向仪表板添加筛选器。
• 将筛选器映射到问题的相应列。
更多信息,请参见仪表板筛选器.
-
Metabase学习教程:系统管理-7 API发布在 Metabase学习教程
使用MetabaseAPI
MetabaseAPI简介。
本文介绍如何使用Metabase的API。我们自己使用该API连接前端和后端,因此您可以编写Metabase几乎可以执行的所有操作。
警告:MetabaseAPI可能会更改
开始之前有两个注意事项:- API可能会更改。API与前端紧密耦合,在不同版本之间可能会发生变化。端点可能不会有那么大的变化(现有的API端点很少被更改,也很少被删除),但是如果您编写代码来使用API,您可能需要在将来更新它。
- API没有版本。意思是:它可以在不同的版本之间进行更改,因此不要期望为了使用“稳定”的API而停留在Metabase的特定版本上。
MetabaseAPI入门
为了简单起见,我们将使用古老的命令行实用程序curl对于我们的API调用示例;您还可以考虑使用一个专用工具来开发API请求(比如Postman). 要跟上,你可以启动一个新的Metabase本地实例到处玩。
使用session token验证您的请求
你需要一个session token以验证您的请求,否则Metabase将拒绝与您交谈。若要获取session token,请向/api/session具有用户名和密码的终结点:
curl -X POST
-H "Content-Type: application/json"
-d '{"username": "person@metabase.com", "password": "fakepassword"}'
http://localhost:3000/api/session
如果使用的是远程服务器,则需要替换localhost:3000你的服务器地址。此请求将返回一个JSON对象,该对象的键名为id以及令牌作为密钥的值,例如:
{“id”:“38f4939c-ad7f-4cbe-ae54-30946daf8593”}
您将需要在后续请求的标头中包括该session token,如下所示:
"X-Metabase-Session: 38f4939c-ad7f-4cbe-ae54-30946daf8593"
关于会话的一些注意事项:
• 默认情况下,会话有效期为14天。您可以通过设置环境变量来配置此会话持续时间MB_SESSION_AGE(值以分钟为单位)。
• 你应该缓存凭据重复使用它们直到它们过期,因为登录是安全的速率限制的。
• 无效和过期的session token返回401(未授权)状态代码。
• 优雅地处理401状态码。我们建议您编写代码以获取新的session token,并在API返回401 status code.
• 有些端点要求用户是管理员,也称为超级用户。需要管理员或超级用户状态(admin=superuser)的终结点通常在其文档中这样说。他们将返回一个403 (Forbidden) status code 如果当前用户不是管理员。
• 如果您想使用替代身份验证机制请随意投票功能请求.
获取请求示例
下面是一个示例API请求(注意session token),它将/api/user/current端点,它返回有关当前用户的信息:
curl -X GET
-H "Content-Type: application/json"
-H "X-Metabase-Session: 38f4939c-ad7f-4cbe-ae54-30946daf8593"
http://localhost:3000/api/user/current
上面的请求返回一个JSON对象(格式化为可读性):
{
"email": "person@metabase.com",
"ldap_auth": false,
"first_name": "Human",
"locale": null,
"last_login": "2020-08-31T13:08:50.203",
"is_active": true,
"is_qbnewb": false,
"updated_at": "2020-08-31T13:08:50.203",
"group_ids": [
1,
2
],
"is_superuser": true,
"login_attributes": null,
"id": 1,
"last_name": "Person",
"date_joined": "2020-08-19T10:50:46.547",
"personal_collection_id": 1,
"common_name": "Human Person",
"google_auth": false
}
POST请求示例
您还可以使用一个文件来存储POST请求的JSON负载。这使得您可以很容易地对API发出一组预定义的请求。
curl -H @header_file.txt -d @payload.json http://localhost/api/card
下面是一个JSON文件的示例@payload.json在上面的命令中)创建一个问题:
{
"visualization_settings": {
"table.pivot_column": "QUANTITY",
"table.cell_column": "SUBTOTAL"
},
"description value": "A card generated by the API",
"collection_position": null,
"result_metadata": null,
"metadata_checksum": null,
"collection_id": null,
"name": "API-generated question",
"dataset_query": {
"database": 1,
"query": {
"source-table": 2
},
"type": "query"
},
"display": "table"
}
该请求生成了如图1所示的问题。
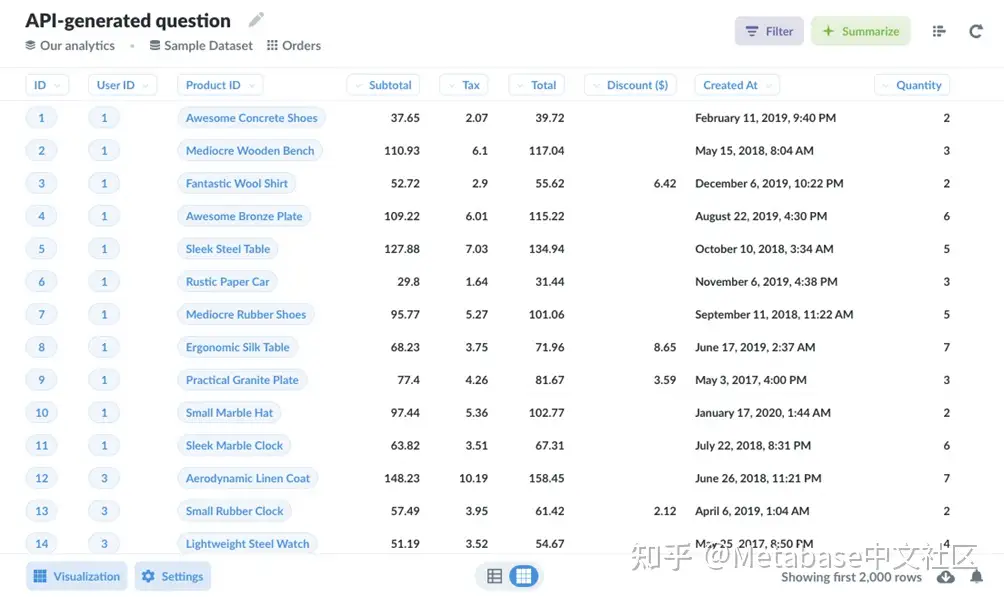
图1.API生成的Metabase中的问题:示例数据库中的Orderds表
使用开发人员工具查看Metabase如何发出请求
如果自动生成的API文档不清楚,可以使用Firefox、Chrome和Edge等浏览器附带的开发工具来查看Metabase的请求和响应(图2)。
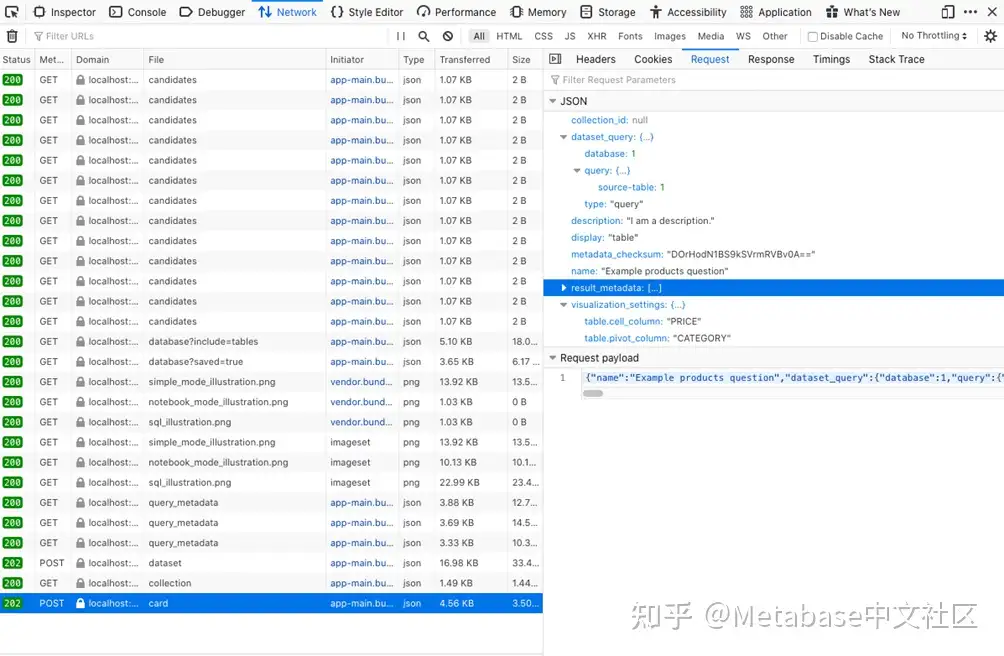
图2。使用Firefox的“网络”选项卡检查用户单击以保存在查询编辑器中创建的问题时Metabase发送的JSON请求负载。
在Metabase应用程序中,执行要编写脚本的操作,例如添加用户或创建仪表板。然后使用浏览器中的开发人员工具查看执行该操作时向服务器发出的请求Metabase。
使用MetabaseAPI可以做的一些事情
设置Metabase实例
除了使用环境变量,您可以使用MetabaseAPI来设置Metabase的实例。一旦您使用首选方法,并且Metabase服务器已启动并正在运行,您可以通过发布到特定端点来创建第一个用户(作为管理员),/api/setup.这个/api/setup终结点:
• 将第一个用户创建为管理员(超级用户)。
• 让他们登录。
• 返回会话ID。
然后可以使用/api/setup端点,使用/api/emai端点,并使用/api/setup/admin_checklist验证安装进度的终结点。有关管理面板中检查表的图形表示,请参见图3。
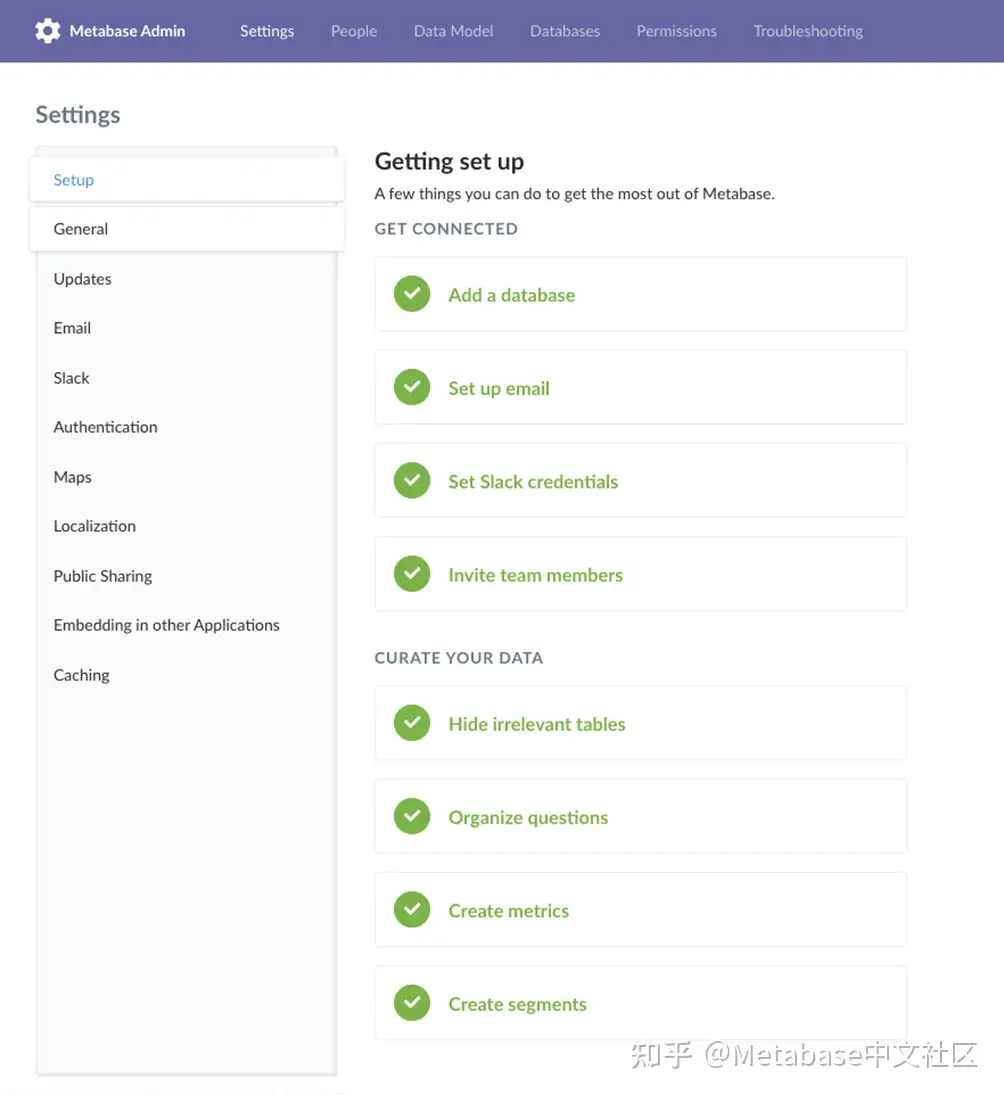
图3.Admin用于设置Metabase以充分利用应用程序的清单。
添加数据源
您可以使用POST /api/database/,并使用/api/setup/validate终结点。将数据库连接到Metabase实例后,可以重新扫描数据库并更新架构元数据。你甚至可以加上我们的信任示例数据库作为实例的新数据库POST /api/database/sample_database.
下面是一个示例数据库创建调用红移数据库。
curl -s -X POST
-H "Content-type: application/json"
-H "X-Metabase-Session: ${MB_TOKEN}"
http://localhost:3000/api/database
-d '{
"engine": "redshift",
"name": "Redshift",
"details": {
"host": "redshift.aws.com",
"port": "5432",
"db": "dev",
"user": "root",
"password": "password"
}
}'
设置用户、组和权限
你可以使用/api/user要创建、更新和禁用用户的终结点,或/api/permissions要设置组或的终结点向其添加用户。以下是创建用户的curl命令示例:
curl -s "http://localhost:3000/api/user"
-H 'Content-Type: application/json'
-H "X-Metabase-Session: ${MB_TOKEN}"
-d '{
"first_name":"Basic",
"last_name":"User",
"email":"basic@somewhere.com",
"password":"Sup3rS3cure_:}"
}'
生成报告
在Metabase中,“报告”被称为仪表板。您可以使用/api/dashboard终结点。你可以创建新仪表板具有POST /api/dashboard/,和将保存的问题添加到仪表板与[POST/api/dashboard/:id/cards].
有用的端点
下面“端点”列中的链接将带您转到该端点可用的第一个操作,该操作通常按字母顺序为“删除”操作。您可以在API文档中向下滚动查看该端点的操作和url的完整列表,并查看每个操作和url的描述。
域 说明 终结点
集合
集合是组织仪表盘、保存的问题和定时器的好方法。 /api/collection
仪表板
仪表板是由一组问题和文本卡组成的报告。 /api/dashboard数据库
获取数据库、字段、模式、主(实体)键、表列表等。 /api/database电子邮件
更新电子邮件设置并发送测试电子邮件。 /api/email嵌入
使用签名的jwt获取嵌入式卡和仪表板上的信息。 /api/embed指标
指标是节省的计算(如收入)。创建和更新指标,返回相关实体,恢复到以前的版本,等等。 /api/metric权限
Metabase使用组管理对数据库和集合的权限。创建权限组、向组添加和删除用户、检索所有权限组的图形,等等。 /api/permissions搜索 在卡片(问题)、仪表板、集合和脉冲中搜索子字符串。 /api/search
分段
分段是过滤器的命名集(如“活动用户”)。创建和更新段,恢复到以前的版本,等等。 /api/segment会话
使用令牌重置密码,使用Google Auth登录,发送密码重置电子邮件,等等。 /api/sessions设置
创建/更新全局应用程序设置。 /api/setting查询 使用API执行查询并以指定格式返回查询结果。 /api/dataset
问题
问题(API中称为卡片)是查询及其可视化结果。 /api/card还有一些很酷的端点需要检查,比如api/database/:virtual-db/metadata,这是用来“愚弄”前端,以便它可以治疗保存的问题就好像它们是虚拟数据库中的表一样。这就是Metabase如何让您将保存的问题当作数据源使用。
文件包含API端点的完整列表以及每个端点的文档,所以仔细研究一下,看看您能找到哪些其他很酷的端点。
端点引用会使用Metabase的新版本定期更新。也可以通过运行以下命令生成引用:
java -jar metabase.jar api-documentation
运行自定义查询
用我们的查询编辑器保存在我们自定义的基于JSON的查询语言MBQL中。您可以查看MBQL的限定语法,以及一个(不完整)MBQL参考文件了解MBQL背后的一些设计理念。
为了熟悉MBQL,我们建议使用Metabase应用程序来构建GUI问题,然后使用浏览器的开发人员工具查看Metabase如何使用查询格式化请求正文。
三种语言示例
Curl是探索api的一个方便工具,但是如果您要将Metabase集成到一个大型数据生态系统中,您可能会使用其他工具。演示如何使用Python、R和Node访问API。js,让我们提出两个问题。第一个(如图4所示)按类别查找超过100美元的订单的平均税前价值。它是公开共享的-本教程解释如何做到这一点。第二个问题,如图5所示,统计数据库中的人数。它是不共享的:我们把它包括进来,以展示如何区分共享问题和非共享问题。
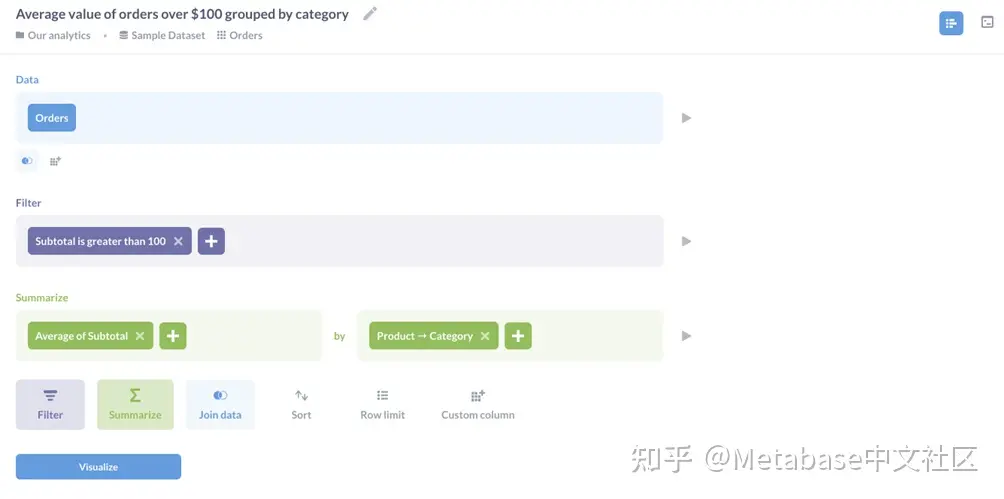
图4。按产品类别计算100美元以上订单平均价值的公开问题查询编辑器。
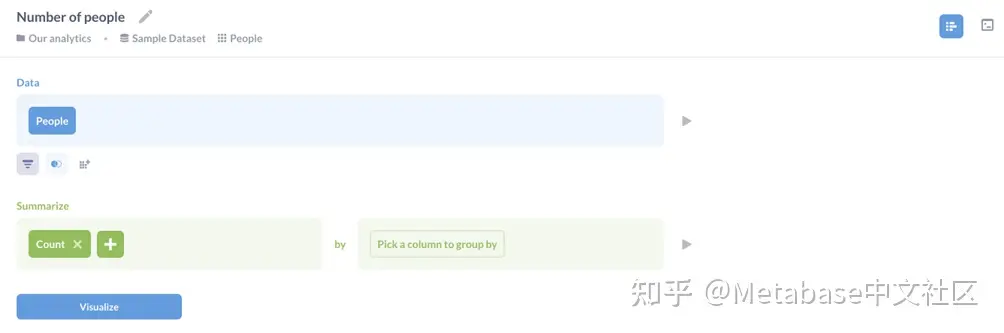
图5。计算数据库中人数的非公开问题的查询编辑器。
Python
我们的第一个示例是用Python编写的。像大多数数据科学项目一样,它使用请求用于发送HTTP请求和Pandas为了管理表格数据,我们从导入这些数据开始:
import requests
import pandas as pd
下一步是获取一个session token来验证将来的所有请求。(该示例使用我的凭据您可以用您的用户名和密码替换它们,但请确保别这样将这些值提交到版本控制存储库。)为了从结果中获取令牌,我们将后者转换为JSON并查找ID。我们将其存储在字典中,并使用正确的密钥以备将来使用:
response = requests.post('http://localhost:3000/api/session',
json={'username': 'greg@metabase.com',
'password': 'database1'})
session_id = response.json()['id']
headers = {'X-Metabase-Session': session_id}
我们现在可以询问Metabase哪些问题具有公共id,也就是说,哪些问题已经被共享,以便我们可以远程调用它们。正如下面的代码所示,当我们要求所有的卡片时,我们会得到一个包含所有问题信息的列表;只有那些有public_uuid字段可调用:
response = requests.get('http://localhost:3000/api/card',
headers=headers).json()
questions = [q for q in response if q['public_uuid']]
print(f'{len(questions)} public of {len(response)} questions')
果然,输出告诉我们有两个问题,但只有一个是公开的:
1 public of 2 questions
让我们获取一些关于公共问题的信息并打印标题:
uuid = questions[0]['public_uuid']
response = requests.get(f'http://localhost:3000/api/public/card/{uuid}',
headers=headers)
print(f'First title: {response.json()["name"]}')
First title: Average value of orders over $100 grouped by category最后,我们可以从列表中的第一个问题中提取数据。这个'数据'key在JSON响应中有很多信息;我们最感兴趣的是子关键字下的值'行',它将结果表存储在通常的列表列表表单中。让我们将其转换为Pandas数据帧并打印它:
response = requests.get(f'http://localhost:3000/api/public/card/{uuid}/query',
headers=headers)
rows = response.json()['data']['rows']
data = pd.DataFrame(rows, columns=['Category', 'Average'])
print('First data')
print(data)
First data
Category Average
0 Doohickey 114.679742
1 Gadget 123.530916
2 Gizmo 120.897286
3 Widget 122.078721和潮人在一起
我们示例的R版本与Python版本具有相同的结构。像大多数数据科学家一样,我们使用tidyverse库族,让我们一起加载这些库httr对于管理HTTP请求,jsonlite用于解析JSON,以及glue对于字符串格式:
library(tidyverse)
library(httr)
library(jsonlite)
library(glue)
我们再次获得会话ID并将其保存以备将来使用:
data <- POST(
'http://localhost:3000/api/session',
body = list(username = 'greg@metabase.com', password = 'database1'),
encode = 'json'
) %>%
content(as = 'text', encoding = 'UTF-8') %>%
fromJSON()
session_id <- data$id
headers <- add_headers('X-Metabase-Session' = session_id)
然后我们得到所有问题的信息,并询问哪些问题是公开的:
data <- GET('http://localhost:3000/api/card', headers) %>%
content(as = 'text', encoding = 'UTF-8') %>%
fromJSON()
num_questions <- data %>%
nrow()
num_public <- data %>%
pull(public_uuid) %>%
discard(is.na) %>%
length()
glue('{num_public} public of {num_questions} questions')
1 public of 2 questions
显示第一张公共卡的标题会产生与Python相同的结果,这令人放心:
uuid <- data %>%
pull(public_uuid) %>%
discard(is.na) %>%
first()
data <- glue('http://localhost:3000/api/public/card/{uuid}') %>%
GET(headers) %>%
content(as = 'text', encoding = 'UTF-8') %>%
fromJSON()
glue('First title: {data$name}')
First title: Average value of orders over $100 grouped by category
当我们将卡转换为tibble时,与该卡相关联的数据也是相同的,尽管R的默认显示没有提供足够多的小数位数:
data <- glue('http://localhost:3000/api/public/card/{uuid}/query') %>%
GET(headers) %>%
content(as = 'text', encoding = 'UTF-8') %>%
fromJSON()
rows <- data$data$rows
colnames(rows) <- c('Category', 'Average')
rows <- rows %>% as_tibble()
rows$Average <- as.numeric(rows$Average)
glue('First data')
rows
First dataA tibble: 4 x 2
Category Average
<chr> <dbl>
1 Doohickey 115.
2 Gadget 124.
3 Gizmo 121.
4 Widget 122.
Node.js
JavaScript是一种越来越流行的服务器端脚本语言,但与Python和R不同,JavaScript缺少一个用于数据表的单一主流库。对于我们喜欢的大型项目data-forge,但对于小例子,我们坚持Dataframe-js我们也使用 got对于HTTP请求而不是旧的request包,因为后者现在已被弃用。最后,因为我们发现async/await语法比承诺或回调更容易阅读,我们将所有代码放在async然后立即调用的函数:
const got = require("got");
const DataFrame = require("dataframe-js").DataFrame;const main = async () => {
// ...program goes here...
};main();
我们再次从自我认证开始:
// Get a session token to authenticate all future requests.
let response = await got.post("http://localhost:3000/api/session", {
json: { username: "greg@metabase.com", password: "database1" },
responseType: "json",
});
session_id = response.body.id;
headers = { "X-Metabase-Session": session_id };
然后,我们会询问完整的问题列表,并对其进行筛选以选择公共问题:
response = await got.get("http://localhost:3000/api/card", {
responseType: "json",
headers: headers,
});
// filter for public questions
questions = response.body.filter((q) => q.public_uuid);
console.log(${questions.length} public of ${response.body.length} questions);
1 public of 2 questions
第一张公共卡仍然有我们以前见过的标题:
const uuid = questions[0].public_uuid;
response = await got.get(http://localhost:3000/api/public/card/${uuid}, {
responseType: "json",
headers: headers,
});
console.log(First title: ${response.body.name});
First title: Average value of orders over $100 grouped by category
当我们把它的数据拉下来时,我们得到的是相同的值,尽管数字的显示方式略有不同:
response = await got.get(
http://localhost:3000/api/public/card/${uuid}/query,
{
responseType: "json",
headers: headers,
},
);
const rows = response.body.data.rows;
const df = new DataFrame(rows, ["Category", "Average"]);
df.show();
| Category | Average || Doohickey | 114.67... |
| Gadget | 123.53... |
| Gizmo | 120.89... |
| Widget | 122.07... |
玩得高兴
如果您觉得本教程很有趣,您可以启动Metabase的本地实例,尝试API,玩得开心!如果你被卡住了,看看我们的论坛看看是否有人遇到了类似的问题,或张贴新的问题。 -
Metabase学习教程:系统管理-6 扩展发布在 Metabase学习教程
Metabase可扩展性
扩展Metabase以支持更多人和数据库的最佳实践。
Metabase是一个可扩展的、经过实战的软件,被成千上万的公司用来提供高质量的自助服务分析。它通过水平扩展支持高可用性,而且它是开箱即用的高效工具:一台拥有4gb内存的单核机器可以将Metabase扩展到数百个用户。
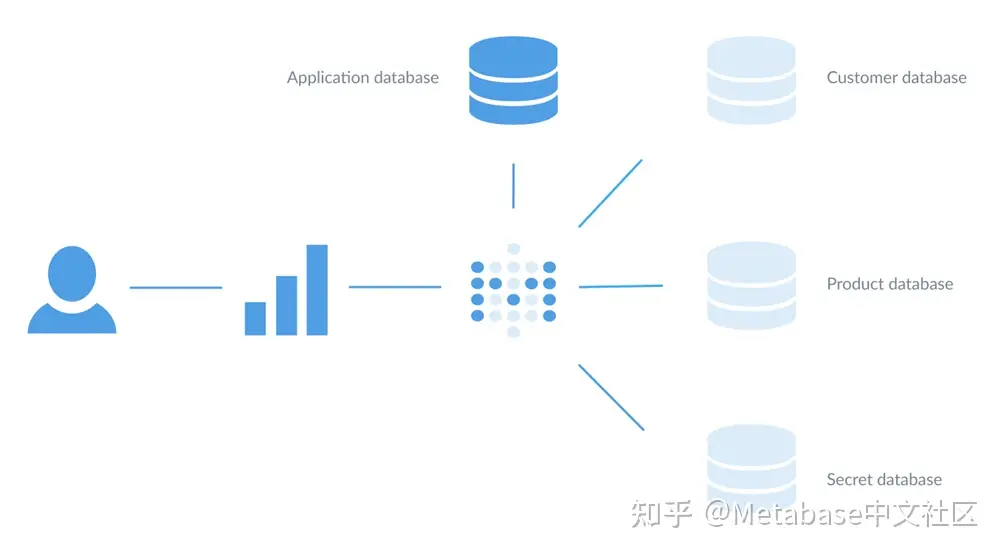
图1。连接到多个数据库及其应用程序数据库的单个Metabase实例,该数据库存储问题、仪表板和其他特定于Metabase的数据。随着增长,可以轻松添加更多Metabase实例。
本文提供了有关如何随着用户和数据源数量的增加而在生产中保持Metabase平稳运行的高级指导和最佳实践。每个数据系统都是不同的,所以我们只能在较高的层次上讨论扩展策略,但是您应该能够将这些策略转换为您特定的环境和使用情况。
影响Metabase性能和可用性的因素
Metabase在垂直和水平方向上都可以很好地缩放,但它只是数据仓库,系统的总体性能将取决于系统的组成和使用模式。影响您使用Metabase体验的主要因素包括:
• 连接到Metabase的数据库数。
• 每个数据库中的表数。
• 数据仓库的效率。
• 仪表板中的问题数。
例如,如果问题需要运行数据库需要30分钟才能完成的查询:只需要30分钟。解决方案是重新评估你对这些数据的需求(你真的每次都需要这些信息吗?)或者找到提高数据库性能的方法,例如重新组织、索引或缓存数据。
数据库和表的数量也会影响客户机性能,但仅在管理数百个数据库和/或数千个表的大规模情况下,如元数据它本身可能有很多问题需要查询。为了使性能在这个范围内保持平稳,您可以管理Metabase同步其元数据的时间与您连接的数据库。
现在,让我们确保您的Metabase应用程序能够很好地适应规模。
垂直缩放
垂直缩放是暴力手段。给Metabase更多的内核和内存,它将有更多的可用资源来完成它的工作。如果遇到与应用程序本身相关的性能问题(即,与数据库的宽度和大小无关),则在功能更强大的计算机上运行Metabase可以提高性能。
也就是说,Metabase已经是开箱即用的高效工具。例如,对于AWS上的starterMetabase实例,我们建议使用平台即服务技术在t3.small实例,并从那里扩展。那是一台双核机器,有2GB的内存。4-8gb的计算机应该可以处理数百个用户,如果需要,可以增加内核数量和千兆字节内存。
虽然添加更多的内核和内存会很有效,但是通常最好使用水平伸缩来支持更多的用户。原因是每个Metabase实例都内置了数据库连接限制,以防止实例用请求压倒数据仓库。你可以增加连接数可用于您的实例,但我们仍建议使用多个实例。
水平缩放
水平缩放涉及到将Metabase的多个实例与负载平衡器一起运行,以将流量定向到实例。Metabase是为水平扩展而设置的,因此不需要任何特殊配置来运行Metabase的多个实例。
水平扩展的主要用例是提高可靠性(也称为“高可用性”),但是水平扩展也可以提高多用户性能。当负载平衡时,高流量、CPU绑定的Metabase实例的某些流量被定向到其他实例时,其性能会更好(更快),因为CPU负载将分布在多台计算机上。
Metabase与本地H2数据库存储你的申请数据(所有的问题,仪表板,日志和其他Metabase数据),但在生产环境中运行时,应升级到关系数据库,如PostgreSQL在单独的服务器上运行。事实上,当水平扩展时,必须使用在单独服务器上运行的关系数据库来存储应用程序数据。这样,Metabase的所有实例都可以共享一个公共数据库。对于所有生产实例,我们建议在单独的服务器上为所有生产实例使用外部数据库,即使您只运行过一个Metabase实例,因此外部数据库不会增加水平扩展的成本。
Metabase使用外部应用程序数据库存储用户会话数据,这样当一个或所有Metabase实例关闭时,用户不必担心丢失已保存的工作,管理员也不必处理配置粘滞会话以确保用户连接到正确的Metabase实例。负载平衡器会将用户路由到一个可用的实例,这样他们就可以继续工作了。
利用基于时间的水平缩放
一些客户根据一天中的时间调整Metabase实例的数量。例如,一些公司会在早上启动Metabase的多个实例,以便在人们登录并运行其上午的仪表板时处理突发的流量,然后在下午(或晚上或周末)关闭这些实例,以节省云开支。
如果您使用我们的弹性部署,您可以配置两者基于资源的缩放触发器和基于时间的缩放。对于其他环境,例如 Kubernetes 或 Google Cloud Platform,您需要参考每个系统的相应文档来设置类似的自动调整规则。
简单的负载平衡
负载平衡器将流量定向到多个Metabase实例,以确保每个请求获得最快的响应。如果Metabase的一个实例暂时关闭,负载平衡器将请求路由到另一个可用实例。
使用Metabase设置负载平衡器很简单。Metabase API公开运行状况检查终结点,/api/health,负载平衡器可以调用它来确定Metabase实例是否已启动并响应请求。如果实例正常,则端点将返回一个HTTP状态代码200 OK。否则,负载平衡器将知道将请求路由到另一个实例。
请参阅我们的指南在AWS弹性架构上运行Metabase查看设置负载平衡器以使用/api/health终结点。
数据仓库调整
构建数据仓库超出了本文的讨论范围,但是您应该知道,Metabase中的查询速度只会与数据库返回数据的速度一样快。如果您遇到的问题需要大量的数据,而这些数据需要很长时间才能检索到,那么无论Metabase有多快,这些查询时间都会影响您的体验。
以下是一些可以提高数据仓库性能的方法:
• 以预测人们会问的问题的方式组织数据。确定您的使用模式并以一种便于返回组织中常见问题的结果的方式存储数据。编写ETL以创建新表,这些表将来自多个源的频繁查询的数据集中在一起。
• 调整数据库。阅读数据库的文档,了解如何通过索引、缓存和其他优化来提高数据库的性能。
• 过滤数据.鼓励人们使用过滤器提问数据。他们还应该利用Metabase的数据探索工具(包括记录预览),这样他们只查询与他们试图回答的问题相关的数据。
• 决定是使用数据库还是数据仓库。人们通常从使用像MySQL数据库或PostgreSQL。虽然这些数据库的扩展性相当好,但它们通常没有针对Metabase将使用的分析查询类型进行优化。像这样的操作sum或max当你达到一定的程度时会减速。随着分析应用的增长,您可能会发现需要探索专用的数据仓库,例如 Amazon Redshift, Google BigQuery, 或 Snowflake..
Metabase应用程序最佳实践
以下是一些策略,可以最大限度地利用Metabase应用程序:
• 只需要你需要的数据.
• 使用托管关系数据库存储Metabase应用程序数据.
• 缓存查询.
• 寻找瓶颈.
• 增加到Metabase应用程序数据库的最大连接数.
• 增加到每个数据库的最大连接数.
• 只在需要时与数据库同步.
• 升级至Metabase的最新版本.
• 使您的浏览器保持最新.
只需要你需要的数据
如果人们正在运行大量返回大量记录的查询,那么Metabase的速度是否快并不重要:用户只会以数据仓库返回所请求记录的速度获取数据。有时,人们对仪表板的要求太高了:当一个包含50个问题的仪表板加载时,它会同时发送50个请求数据的请求。根据数据库的大小,返回这些记录可能需要相当长的时间。
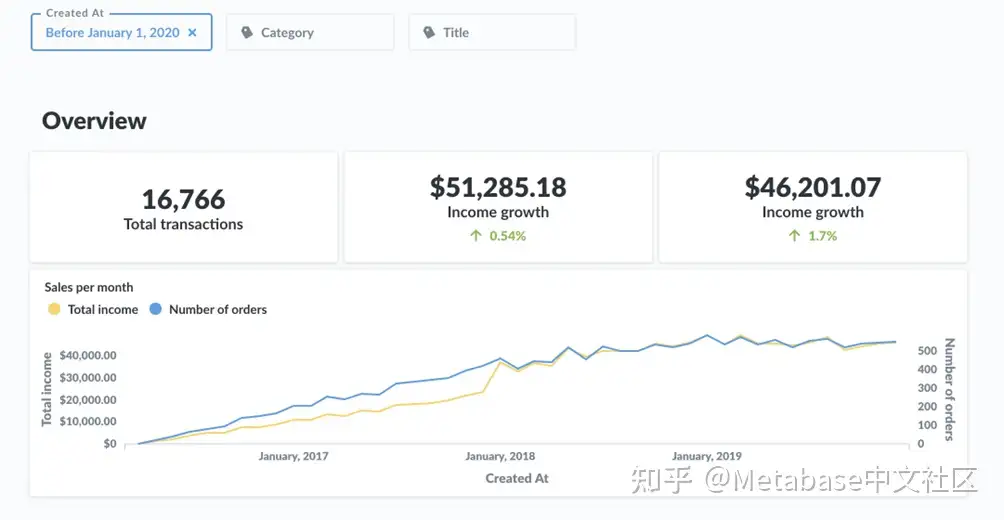
图2。使用Metabase中包含的示例数据库中的数据的筛选器小部件的示例仪表板。
但这不是全部。Metabase不会因为您在仪表板中提出更多问题而减慢速度。如果您的问题没有获取大量数据,或者您的数据仓库可以在一秒钟内返回结果,那么50个问题将很快加载。
不过,总的来说,鼓励人们保持仪表盘的重点。仪表板是用来讲述你的数据的故事,你可以用几个问题(甚至一个问题)来讲述一个好故事。利用Metabase的数据探索工具来了解您的数据(例如在表中预览记录的能力),这样您就可以只拨入回答问题所需的记录。
因此,确保每个问题都是完成仪表板所必需的,并且在跨时间或跨空间查询数据时要特别注意,因为您可以通过将问题限制在较短的时间跨度或较小的区域来过滤掉大量不必要的数据。
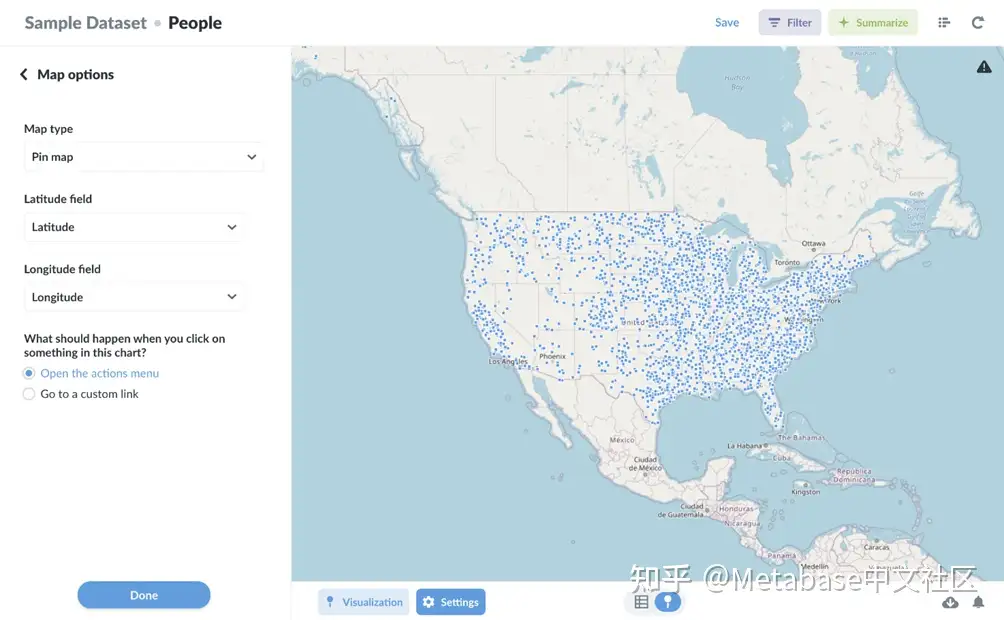
图3。使用图钉图显示经纬度的示例问题。地理空间数据可以快速累积,从而减慢查询时间,因此只过滤所需的数据非常重要。
使用托管关系数据库存储Metabase应用程序数据
应用程序数据库存储所有问题、仪表板,集合、权限以及与Metabase应用程序相关的其他数据。您可以使用关系数据库(如PostgreSQL或MySQL)来管理您的应用程序数据库,但我们推荐一个托管解决方案,如AWS RDS。RDS将自动备份,并使您更容易在扩展时调整存储和计算,从而使您少担心一件事。托管数据库解决方案对于自托管的客户特别有用,商业版利用了Metabase的优势审核功能,因为启用审核将增加应用程序数据库中的数据Metabase存储量。
缓存查询
你可以配置缓存存储最近提出的问题的结果,以便不需要重新计算。Metabase将向用户显示结果的时间戳,如果用户想重新运行查询,可以手动刷新问题的结果。缓存适用于不经常更新的结果。
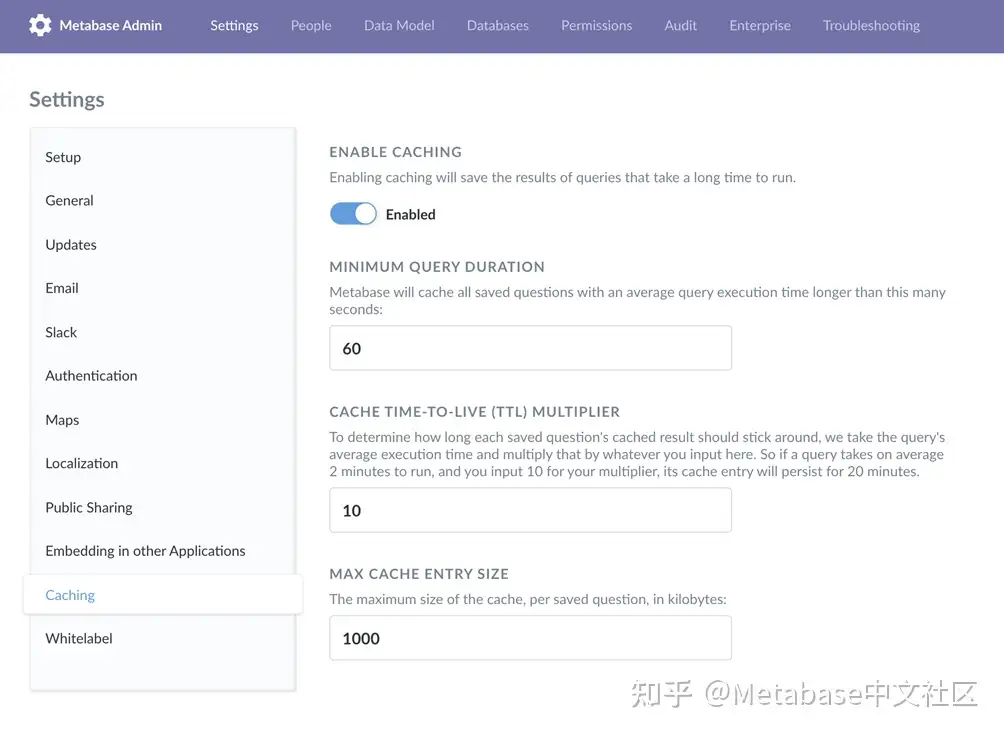
图4。启用缓存以存储问题结果。
寻找瓶颈
一些商业版本提供审计工具用于监视应用程序的使用和性能。例如,您可以查看有多少问题正在被询问,由谁提出,以及这些问题运行了多长时间,这有助于确定任何需要注意的瓶颈。
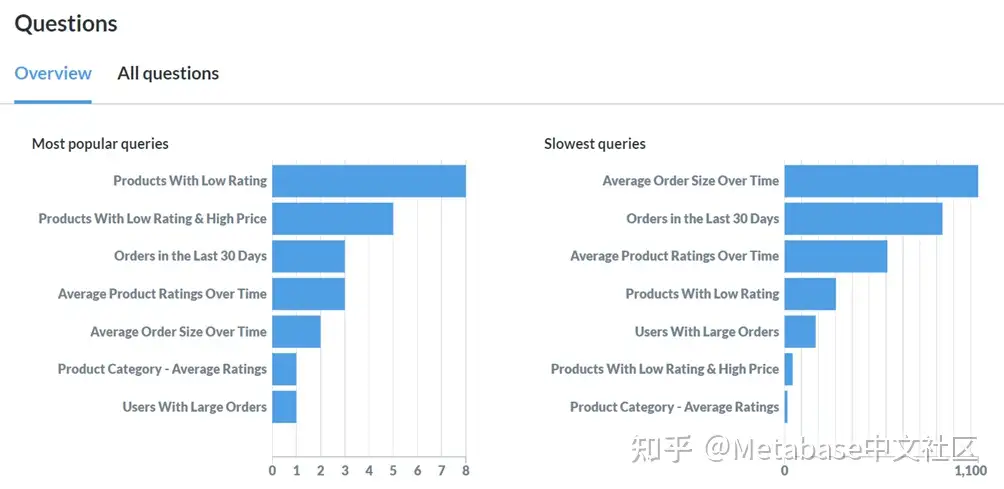
图5。使用审核工具查看最流行(也是最慢)的问题。
增加到Metabase应用程序数据库的最大连接数
Metabase应用程序数据库的默认连接数MB_APPLICATION_DB_MAX_CONNECTION_POOL_SIZE环境变量,当前默认设置为15。如果您的使用经常消耗所有这些连接,则可以通过增加最大连接数来提高性能。或者,您可以通过水平伸缩来增加连接的数量(例如,如果您添加了一个额外的Metabase实例,那么您实际上就向应用程序数据库添加了另外15个连接)。
您可以通过以下方式检查连接数:查看日志,并检查线路,如... App DB connections: 12/15。在该示例中,Metabase正在使用15个可用应用程序数据库连接中的12个。
增加到每个数据库的最大连接数
类似地,单个Metabase实例到每个数据库的默认最大连接数为15,即每个数据库的最大连接数为15,因此,如果已将Metabase连接到两个数据库,则最多可以连接30个。
可以通过更改MB_JDBC_DATA_WAREHOUSE_MAX_CONNECTION_POOL_SIZE环境变量。与上面的应用程序数据库连接一样,您还可以通过水平伸缩来增加连接的数量。每个附加的Metabase实例都会将最大连接数增加15个(或您设置的任何最大值)。要了解更多信息,请参阅我们的环境变量文件.
只在需要时与数据库同步
默认情况下,Metabase每小时执行一次轻量级同步。同步不会复制任何数据。Metabase只是检查以确保表列表,列,并且它在其应用程序数据库中维护的行与数据库中的表、列和行是最新的。
你可以设置这些同步的定时和频率。对于大型数据库,可以考虑限制Metabase执行同步的次数,并将这些同步限制在非高峰时间,尤其是在不经常向数据库添加新表的情况下。
图6。您可以更改Metabase与数据库同步的时间,这可以提高连接到特别大的数据库时的性能。
升级至Metabase的最新版本
如果你还没有,我们推荐你升级至Metabase的最新版本获取最新的性能改进。
通过HTTP/2通过HTTPS服务Metabase
通过HTTPS over HTTP/2为Metabase实例提供服务可以提高性能,因为HTTP/1.1上的浏览器可以将每个域的连接限制为大约6个并发连接,而HTTP/2是在单个连接上多路传输的。更多的可用连接无法修复速度较慢的数据库,或线程已用完的重载Metabase实例,但至少您会知道您的浏览器不会限制您的连接。
使您的浏览器保持最新
Metabase是一个web应用程序,可以从最新和最好的浏览器版本中获益,比如 Firefox, Chrome, Edge, 和Safari..
支持的部署
建立Metabase的方法有很多种;我们的最爱包括:
• AWS弹性豆茎:看看我们的弹性部署Metabase建立指南。我们使用Elastic Beanstalk托管内部Metabase应用程序。
• Docker:参考在Docker上运行Metabase.
Google Cloud Platform, Microsoft Azure, Digital Ocean, Heroku,以及其他云提供商为托管您的Metabase应用程序提供了其他很好的替代方案。
托管Metabase
如果您不想处理Metabase应用程序的照管和馈送,Metabase提供了一个托管解决方案。您仍然需要确保数据源的性能,但不再需要管理Metabase应用程序的运行。
寻求帮助
如果你还有问题,很可能有人已经有了同样的问题。看看Metabase讨论论坛搜索你的问题。如果你找不到解决办法,请提交你自己的问题。 -
Metabase学习教程:系统管理-5 优化发布在 Metabase学习教程
仪表板优化
如何使您的仪表板加载更快。
说到仪表板性能方面,基本上有四种方法可以让仪表板更快地加载:
• 要求更少的数据.
• 缓存问题答案.
• 组织数据以预测常见问题.
• 提出有效的问题。
图1。包含三个筛选器小部件的示例仪表板,它们使用Metabase附带的示例数据库。
下面是一些关于如何获得仪表板加载速度更快。本指南的大部分内容将集中在第三个要点上,或者您如何组织数据来预测数据将用于回答的最常见问题。
关于过早优化是万恶之源的常见警告。我们的建议假设您已经研究了一段时间的数据,并且从数据产生的洞察力中获得了实质性的好处。只有这样,您才应该问,“如何让这个仪表板加载更快?”
要求更少的数据
这一点太明显了,常常被忽视,但它应该是第一个开始的地方。你真的需要你正在查询的数据吗?即使你确实需要这些数据,你多久需要一次?
只需限制查询的数据,例如添加仪表板上的默认筛选器。尤其要注意跨越时间和空间的数据:你真的需要每天查看上一季度的数据吗?或者你真的需要每个国家的每笔交易?
即使你做需要知道这些信息,你每天都需要吗?你能把这个问题转移到另一个通常只每周或每月审查的仪表板上吗?
当我们探索我们的数据集时,我们应该对我们的所有数据开放,但是一旦我们确定了我们的组织需要做出的决策以及我们需要为这些决策提供信息的数据,我们就应该毫不留情地排除那些对我们的分析没有显著改善的数据。
缓存问题答案
如果数据已经加载,则不需要等待。管理员可以将Metabase设置为缓存查询结果,它将存储问题的答案。如果你有一套仪表板,每个人在早上第一件事打开电脑时都会运行,那么提前运行仪表板,仪表板中的问题将使用保存的结果在几秒钟内加载后续运行。人们可以选择刷新数据,但通常这是不必要的,因为大多数情况下人们只需要查看前一天和之前的数据。
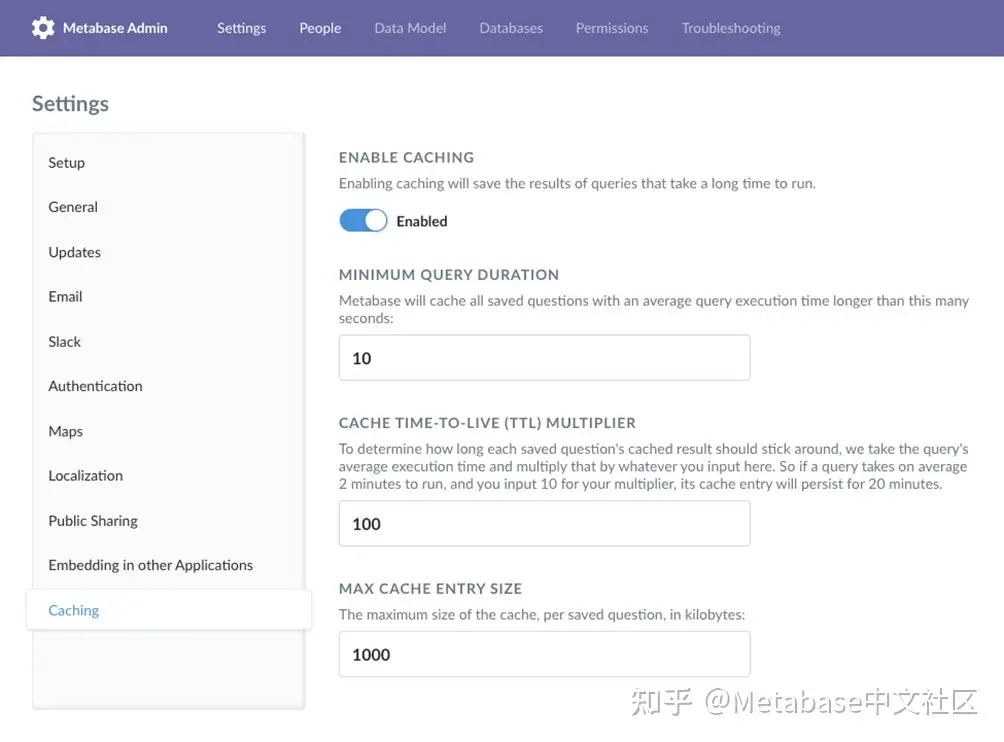
图2。启用缓存以存储运行时间较长的查询的结果。
可以在中配置缓存设置的管理面板。通过这些设置,您可以配置要缓存的最短查询持续时间(因此您只缓存长时间运行的查询)、缓存生存时间(TTL)乘数(以指定缓存应保留多长时间)和最大缓存项大小(以便您可以设置缓存数据量的上限)。
你可以使用Metabase的审计工具要确定人们通常何时运行各种问题,然后使用Metabase的API提前以编程方式运行这些问题(从而缓存它们的结果)。这样,当用户登录并导航到他们的仪表板时,结果将在几秒钟内加载。即使不采取额外的“预热”步骤,当第一个人加载这个缓慢的查询时,它也会被缓存以供其他人使用。
组织数据以预测常见问题
您可以做的下一件最好的事情是以这样一种方式组织您的数据,这样它就可以预测将要提出的问题,这将使您的数据库更容易地检索这些数据。
• 索引经常查询的列.
• 复制数据库.
• 非规范化数据.
• 物化视图:创建新表来存储查询结果.
• 用汇总表提前汇总数据.
• 从JSON中提取数据并将其键插入列中.
• 考虑一个特定于分析的数据库.
除了最后一节之外,其他部分都假设您使用的是传统的关系数据库,如PostgreSQL或MySQL。最后一节是关于移动到一个完全不同的数据库类型,专门为处理分析而优化,这应该是你最后的手段,尤其是对于初创企业。
索引经常查询的列
向数据库添加索引可以显著提高查询性能。但是,正如索引书中的所有内容没有意义一样,索引也会产生一些开销,因此应该从战略上加以利用。
如何战略性地使用索引?查找查询最多的表,以及最常查询的表柱在那些桌子上。你可以参考你的个人数据库来得到这个元数据例如,PostgreSQL通过其 pg_stat_statements 模块。
记住要做一些简单的工作,询问你的Metabase用户哪些问题和仪表板对他们来说是重要的,以及他们是否也遇到了任何“慢”。最经常需要索引的字段要么是基于时间的或基于id的事件数据的思考时间戳,要么是分类数据上的id。
或者,在商业版本,您可以使用Metabase的审计工具,这样就可以很容易地查看谁在运行哪些查询、多长时间以及这些查询返回记录所用的时间。
一旦确定了要索引的表和列,请查阅数据库的文档以了解如何设置索引(例如,以下是PostgreSQL中的索引).
索引很容易设置(和删除)。以下是CREATE INDEX声明:
CREATE INDEX index_name ON table_name (column_name)
例如:
CREATE INDEX orders_id_index ON orders (id)
尝试索引,看看如何提高查询性能。如果您的用户通常使用多个过滤器在单个表上,使用复合索引进行调查。
复制数据库
如果您正在使用一个数据库来处理这两个操作(例如,应用程序事务,如下单、更新配置文件信息等)以及分析(例如,用于支持Metabase仪表板的查询),请考虑创建该数据库的副本生产数据库用作仅用于分析的数据库。将Metabase连接到该副本,每晚更新副本,并让您的分析员离开查询。分析师的长时间运行查询不会干扰生产数据库的日常操作,反之亦然。
除了使您的仪表板更快之外,为数据分析保留一个副本数据库是一个很好的做法,以避免可能长期运行的分析查询影响您的生产环境。
非范式数据
在某些情况下,这可能是有意义的使非范式化一些表(例如,将多个表合并成一个包含更多列的更大的表)。您将最终存储一些冗余数据(例如每次用户下单时都包括用户信息),但分析师不必这样做参加多个表来获取回答问题所需的数据。
物化视图:创建新表来存储查询结果
与物化视图,您将在它们的表中保留原始的、非规范化的数据,并创建新表(通常在下班时间)来存储查询结果,这些查询结果将多个表中的数据组合在一起,以预测分析员将要问的问题。
例如,您可以将订单和产品信息存储在不同的表中。您可以每晚创建(或更新)一个物化视图,该视图将这两个表中最常查询的列组合在一起,并将该物化视图连接到Metabase中的问题。如果您将数据库用于生产和分析,除了消除合并这些数据所需的连接过程外,您的查询将不必与这些表上的生产读写竞争。
物化视图与公共表表达式(CTE,有时称为视图)是物化视图将其结果存储在数据库中(因此可以被索引)。CTE本质上是子查询,每次都要计算。它们可以被缓存,但不存储在数据库中。
然而,物化视图将消耗数据库中的资源,您必须手动更新视图(刷新物化视图[名称]).
用汇总表提前汇总数据
这里的想法是使用物化视图甚至是一组单独的表来创建汇总表使计算量最小化。假设您有一个包含一百万行的表,并且您希望在多个列中聚合数据。您可以基于聚合一个或多个表的集合,它将执行初始(耗时)计算。您不必在一天中多次进行仪表板查询并计算原始数据,而是可以创建问题来查询汇总表以获得前一天晚上计算的数据。
例如,您可以有一个包含所有orders表的orders表,以及一个order summary表,该表每夜更新一次并存储汇总数据和其他聚合数据,例如每周、每月的订单总数等。如果某人想查看用于计算该聚合的单个订单,可以使用自定义目的地将用户链接到做查询原始数据。
从JSON中提取数据并将其键插入列中
我们经常看到组织在关系数据库(如MySQL或PostgreSQL)的一列中存储JSON对象。通常,这些组织存储来自事件分析软件的JSON有效负载,比如分段,或振幅.
尽管有些数据库可以索引JSON(例如,PostgreSQL可以索引JSON二进制文件),但是每次仍然必须获取完整的JSON对象,即使您只对对象中的单个键值对感兴趣。相反,考虑从这些JSON对象中提取每个字段,并将这些键映射到表中的列。
考虑一个为分析而优化的数据库
如果您已经完成了上述所有操作,并且仪表板加载时间的长度仍然影响您及时做出决策的能力,那么您应该考虑使用专门为部署分析查询而构建的数据库。这些数据库称为联机分析处理(OLAP)数据库(有时称为数据仓库).
传统的关系型数据库如PostgreSQL和MySQL是为事务处理而设计的,它们被分类为联机事务处理(OLTP)数据库。这些数据库更适合用作操作数据库,例如为web或移动应用程序存储数据。他们非常擅长处理以下场景:有人向你的网站提交一个深思熟虑的、密切相关的、一点也不煽动性的评论,你的应用程序向你的后端发出一个POST请求,然后将评论和元数据路由到你的数据库进行存储。OLTP数据库可以处理大量并发事务,如评论帖子、购物车签出、概要文件bio更新等。
OLAP和OLTP系统之间的主要区别在于OLAP数据库优化分析查询,如对大量数据的求和、聚合和其他分析操作,以及批量导入(通过ETL工具),而OLTP数据库必须平衡来自数据库的大的读取和其他事务类型:小的插入、更新和删除。
OLAP通常使用列存储。而传统的(OLTP)关系数据库按行存储数据,而使用列存储的数据库(毫不奇怪)按列存储数据。这种列式存储策略使OLAP数据库在读取数据时具有优势,因为查询不必筛选不相关的行。这些数据库中的数据通常组织在事实和维度表,带有(通常是大量的)包含事件的事实表。每个事件都包含属性和外键对维度表的引用,其中包含有关这些事件的信息:涉及的人员、发生了什么、产品信息等等。
Metabase支持几种流行的数据仓库: Google BigQuery, Amazon Redshift, Snowflake, 和 Apache Druid(专门从事实时分析)。Metabase还支持 Presto,它是一个查询引擎,可以与各种不同的数据存储配对,包括 Amazon S3.
开始使用Metabase时,不要太担心底层数据存储。但是随着数据的增长Metabase生长,请留意可能要使用数据仓库调查的指标。例如,Redshift可以查询数PB的数据,并可以扩展到AmazonS3中查询历史数据,而Snowflake则允许您随着组织的增长动态扩展计算资源。